



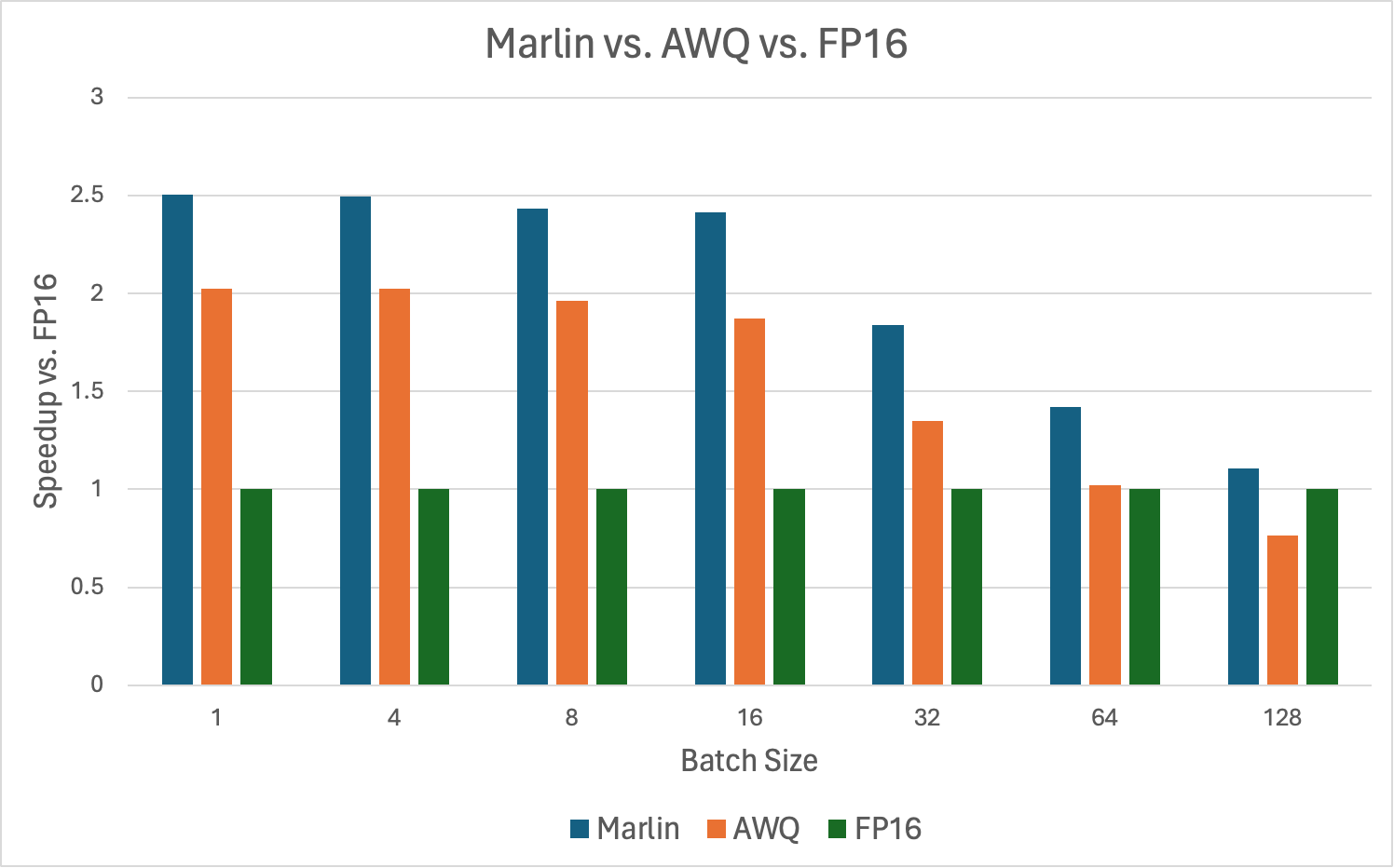
Deploying large language models in production settings is a constant battle between throughput and latency. You want to maximize cluster…
Deploying large language models in production settings is a constant battle between throughput and latency. You want to maximize cluster…Continue reading on Incodeherent » Read More AI on Medium
#AI








+ There are no comments
Add yours