


Accelerating LLM inference by pruning redundant transformer blocks
Accelerating LLM inference by pruning redundant transformer blocksContinue reading on SqueezeBits Team Blog » Read More Llm on Medium
#AI
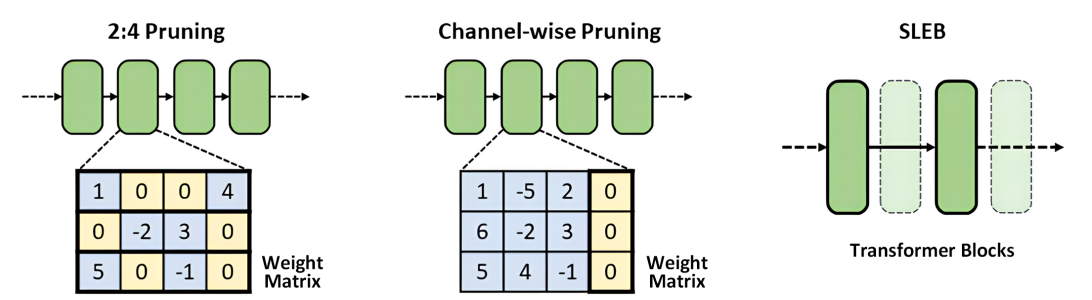
Accelerating LLM inference by pruning redundant transformer blocks
Accelerating LLM inference by pruning redundant transformer blocksContinue reading on SqueezeBits Team Blog » Read More Llm on Medium
#AI









+ There are no comments
Add yours