


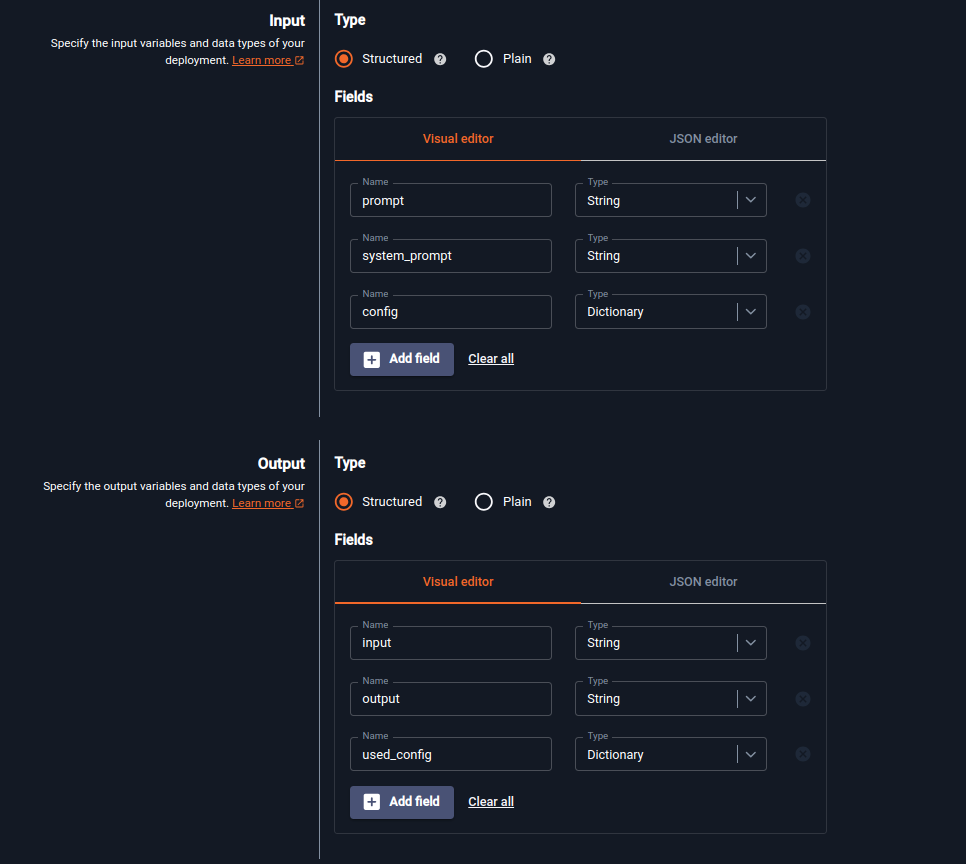
Let’s learn how to increase data throughput for LLMs using batching, specifically by utilizing the vLLM library.
Let’s learn how to increase data throughput for LLMs using batching, specifically by utilizing the vLLM library.Continue reading on UbiOps-tech » Read More Llm on Medium
#AI







+ There are no comments
Add yours