




Post Content
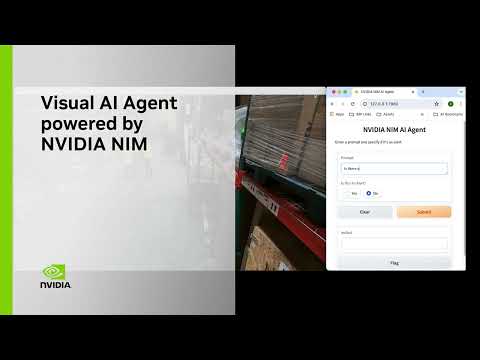
This video demonstrates how Vision Language Models (VLMs) on #NVIDIAJetson enable you to interact with videos and images using natural language, identify events with contextual understanding, and more.
Learn more about visual AI agent: https://nvda.ws/3Wry3Vk
Read the blog: https://nvda.ws/3WeYBaO
#generativeAI Read More NVIDIA
#Techno #nvidia










+ There are no comments
Add yours