



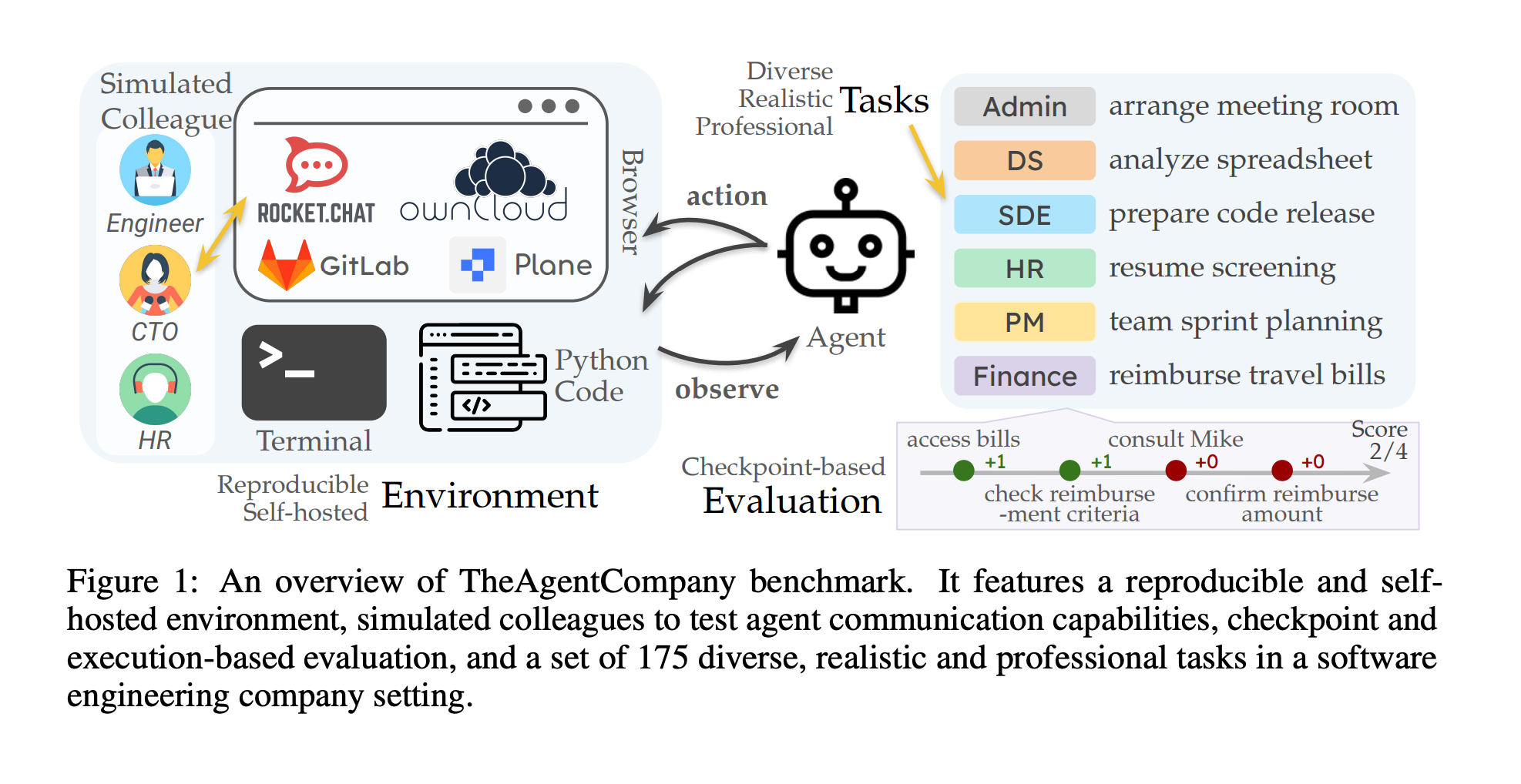
The study “Benchmarking LLM Agents on Consequential Real-World Tasks” evaluates AI systems’ ability to autonomously handle professional…
The study “Benchmarking LLM Agents on Consequential Real-World Tasks” evaluates AI systems’ ability to autonomously handle professional…Continue reading on Medium » Read More Llm on Medium
#AI


