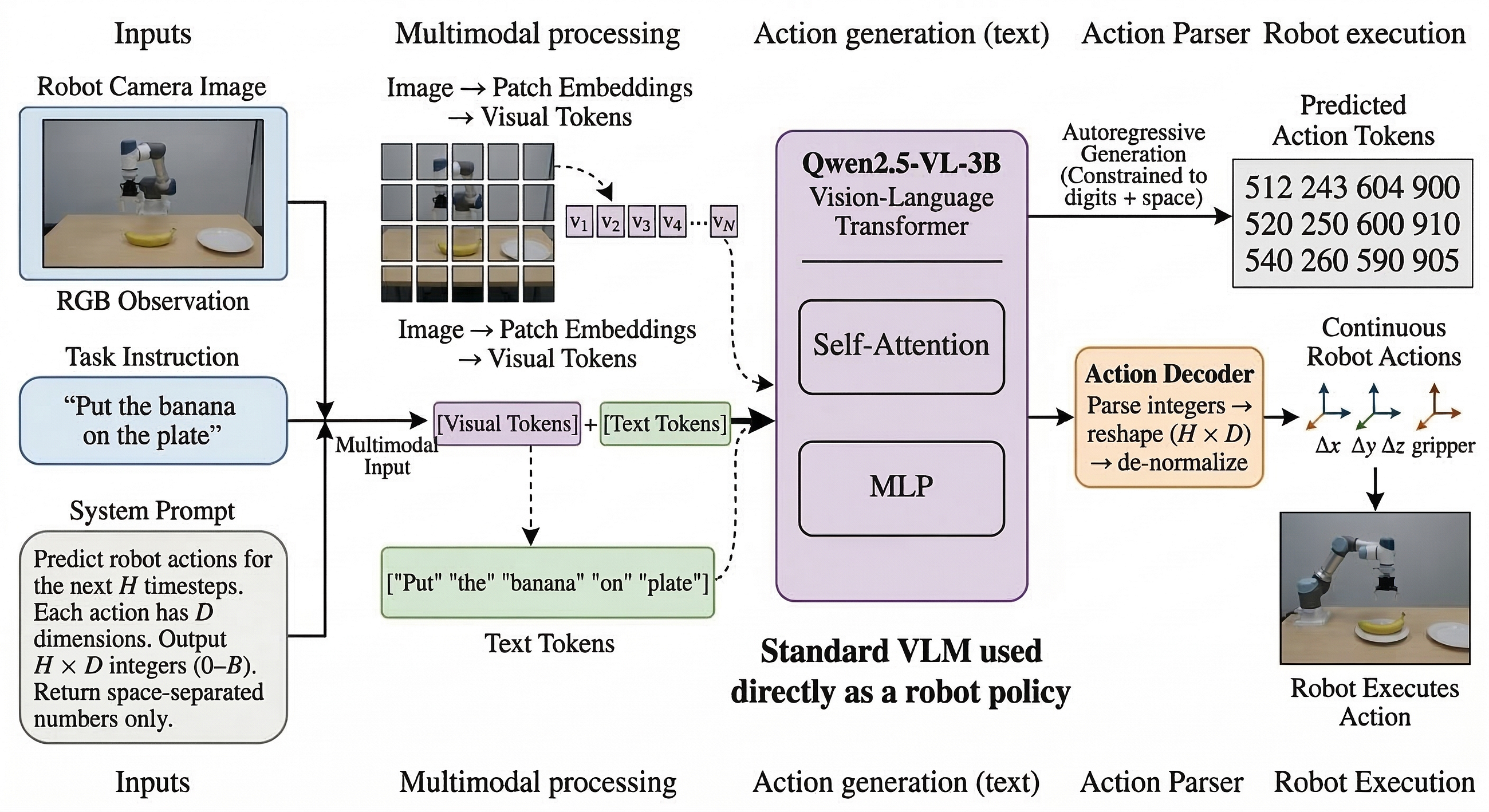


Introduction: MLTrack
Machine learning experimentation requires robust tracking capabilities to ensure reproducibility, comparison, and auditability of models. SAP HANA Cloud’s MLTrack feature provides seamless integration with Predictive Analysis Library (PAL) procedures, enabling automatic logging of critical experiment artifacts. This end-to-end tracking solution captures parameters, datasets, models, metrics, and visualizations in a structured way, transforming how data scientists manage ML workflows.
1. Understanding MLTrack Architecture
MLTrack organizes experiment data through three core tables in the PAL_ML_TRACK schema:
1.1 TRACK_METADATA Table
The experiment registry storing high-level information:
Column
Description
Example Value
TRACK_ID
Unique experiment identifier
“TRACK_TEST”
OWNER
Experiment creator
“DEVELOPER_A”
STATUS
Current state (ACTIVE/FINISHED/FAILED)
“FINISHED”
PROC_NAME
PAL procedure used
“PAL_UNIFIED_CLASSIFICATION”
1.2 TRACK_LOG Table
The detailed experiment diary capturing chronological events:
SELECT * FROM PAL_ML_TRACK.TRACK_LOG
WHERE EXECUTION_ID = ‘TRACK_TEST’
ORDER BY SEQ, EVENT_TIMESTAMP;
Each record includes:
EVENT_KEY: Entity type (Parameter/Dataset/Metric) EVENT_MESSAGE: JSON payload with entity details SEQ: Message sequence number Automatic message splitting for payloads > 5000 characters
1.3 TRACK_LOG_HEADER Table
The tagging system for log records:
SELECT * FROM PAL_ML_TRACK.TRACK_LOG_HEADER
WHERE EXECUTION_ID = ‘TRACK_TEST’
ORDER BY SEQ;
Enables adding custom key-value pairs to any log entry for enhanced categorization.
2. Enabling MLTrack in PAL Procedures
Activate tracking by adding these parameters to your PAL call:
2.1 Control Parameters
Parameter
Type
Values
Functionality
LOG_ML_TRACK
INTEGER
0 or 1
Master switch for MLTrack
LOG_PARAM
INTEGER
0 or 1
Log procedure parameters
LOG_DATASET
INTEGER
0 or 1
Log dataset metadata
LOG_MODEL_SIGNATURE
INTEGER
0 or 1
Log model input/output schemas
LOG_FIGURE
INTEGER
0 or 1
Log visualization data
2.2 Identification Parameters
INSERT INTO PAL_PARAMETER_TBL VALUES
(‘LOG_ML_TRACK’, 1, NULL, NULL),
(‘TRACK_ID’, NULL, NULL, ‘PLAY_PREDICTION_1’),
(‘TRACK_DESCRIPTION’, NULL, NULL, ‘Golf play decision tree’),
(‘DATASET_NAME’, NULL, NULL, ‘Golf_Play_Dataset’),
(‘DATASET_SOURCE’, NULL, NULL, ‘PAL_GOLF_DATA_TBL’);
3. Practical Implementation: Classification Example
3.1 Dataset Setup
CREATE COLUMN TABLE PAL_GOLF_DATA (
“ID” INTEGER,
“OUTLOOK” NVARCHAR(20),
“TEMP” DOUBLE,
“HUMIDITY” DOUBLE,
“WINDY” NVARCHAR(10),
“PLAY” NVARCHAR(20) — Target variable
);
— Sample data insertion
INSERT INTO PAL_GOLF_DATA VALUES
(1, ‘Sunny’, 75, 70.0, ‘No’, ‘Play’),
(2, ‘Rainy’, 68, 80.0, ‘Yes’, ‘Do not Play’);
3.2 Parameter Configuration
CREATE COLUMN TABLE PAL_PARAMS (
“PARAM_NAME” NVARCHAR(100),
“INT_VALUE” INTEGER,
“STRING_VALUE” NVARCHAR(100)
);
INSERT INTO PAL_PARAMS VALUES
(‘FUNCTION’, NULL, ‘RDT’), — Random Decision Tree
(‘MAX_DEPTH’, 10, NULL),
(‘LOG_ML_TRACK’, 1, NULL),
(‘TRACK_ID’, NULL, ‘GOLF_CLS_EXP_1’),
(‘DATASET_SOURCE’, NULL, ‘PAL_GOLF_DATA’);
3.3 Execute PAL Procedure with Tracking
DO
BEGIN
lt_data = SELECT * FROM PAL_GOLF_DATA;
lt_params = SELECT * FROM PAL_PARAMS;
CALL _SYS_AFL.PAL_UNIFIED_CLASSIFICATION_TRACK(
:lt_data,
:lt_params,
lt_model, lt_imp, lt_stat, lt_cmatrix
);
— Persist outputs
INSERT INTO ML_MODELS SELECT * FROM :lt_model;
INSERT INTO FEATURE_IMPORTANCE SELECT * FROM :lt_imp;
END;
4. Accessing Tracked Experiment Data
4.1 Retrieve Experiment Metadata
SELECT * FROM PAL_ML_TRACK.TRACK_METADATA
WHERE TRACK_ID = ‘GOLF_CLS_EXP_1’;
4.2 Analyze Logged Parameters
SELECT EVENT_MESSAGE FROM PAL_ML_TRACK.TRACK_LOG
WHERE EXECUTION_ID = ‘GOLF_CLS_EXP_1’
AND EVENT_KEY = ‘Parameter’;
4.3 Extract Model Evaluation Metrics
SELECT EVENT_MESSAGE->>’$.accuracy’ AS accuracy,
EVENT_MESSAGE->>’$.f1_score’ AS f1
FROM PAL_ML_TRACK.TRACK_LOG
WHERE EXECUTION_ID = ‘GOLF_CLS_EXP_1’
AND EVENT_KEY = ‘METRIC’;
5. Advanced Management: Log Removal
Safely remove experiments using hierarchical deletion:
DO
BEGIN
DECLARE param_tbl TABLE (
PARAM_NAME NVARCHAR(256),
STRING_VALUE NVARCHAR(1000)
);
DECLARE removed_info TABLE (
TRACK_ID NVARCHAR(128),
STATUS NVARCHAR(10)
);
INSERT INTO param_tbl VALUES
(‘REMOVE_MODE’, ‘1’), — Hierarchical removal
(‘TRACK_ID’, ‘GOLF_CLS_EXP_1’),
(‘IS_FORCE’, ‘0’); — Don’t remove active tracks
CALL _SYS_AFL.PAL_REMOVE_MLTRACK_LOG(:param_tbl, removed_info);
SELECT * FROM :removed_info; — Removal confirmation
END;
6. Python Integration with hana_ml
HANA ML Experiment Tracking Example
This code demonstrates how to track machine learning experiments using SAP HANA ML’s tracking capabilities:
1. Imports and Initialization
from hana_ml.artifacts.tracking.tracking import MLExperiments
# Create Unified Classification model using Hybrid Gradient Boosting Trees algorithm
uc = UnifiedClassification(func=”hybridgradientboostingtree”)
2. Experiment Setup
# Define unique experiment identifier
experiment_id = “cls_HGBT_0”
# Optional: Delete previous experiment logs (commented out)
# delete_experiment_log(connection_context, experiment_id)
# Initialize experiment tracking object
class_experiment = MLExperiments(
connection_context=connection_context,
experiment_id=experiment_id,
experiment_description=”cls fit test HGBT”
)
3. Autologging Configuration
# Enable automatic logging for model training
class_experiment.autologging(
uc,
run_name=”diabetes_6″,
dataset_name=”diabetes_train”,
dataset_source=”DIABETES_TBL”
)
Key Features Demonstrated:
MLExperiments Class: Central class for managing experiment metadata and tracking Autologging: Automatically captures: Model parameters Dataset information Training metadata Experiment Organization: Unique experiment_id groups related runs Custom run_name identifies specific executions Dataset Tracking: Explicit linkage between model runs and training data sources
Reference Implementation Details
The underlying MLExperiments class provides these core functions:
Method
Purpose
autologging()
Attach tracking metadata to models
get_current_tracking_id()
Retrieve unique ID for the run
get_tracking_log_for_current_run()
Fetch execution logs
get_tracking_metadata_for_current_run()
Retrieve metadata
7. Visualization and Monitoring
The experiment monitor will display all tracked experiments and experiment runs, obtain the status of each run, and capture detailed internal information about each run.
Monitor experiments
from hana_ml.visualizers.tracking import ExperimentMonitor
experiment_monitor = ExperimentMonitor(connection_context)
experiment_monitor.start()
Conclusion
MLTrack transforms SAP HANA Cloud into a fully traceable MLOps platform, providing:
✅Reproducibility of any ML experiment ✅Comparability of model versions ✅Auditability for compliance requirements ✅Visualization of experiment history ✅Integration with existing PAL workflows
By implementing MLTrack, organizations bridge the gap between experimental machine learning and production-grade MLOps, ensuring every model decision is traceable, explainable, and reproducible.
Related Articles:
Introduction: MLTrack Machine learning experimentation requires robust tracking capabilities to ensure reproducibility, comparison, and auditability of models. SAP HANA Cloud’s MLTrack feature provides seamless integration with Predictive Analysis Library (PAL) procedures, enabling automatic logging of critical experiment artifacts. This end-to-end tracking solution captures parameters, datasets, models, metrics, and visualizations in a structured way, transforming how data scientists manage ML workflows. 1. Understanding MLTrack Architecture MLTrack organizes experiment data through three core tables in the PAL_ML_TRACK schema: 1.1 TRACK_METADATA Table The experiment registry storing high-level information: Column Description Example Value TRACK_ID Unique experiment identifier “TRACK_TEST” OWNER Experiment creator “DEVELOPER_A” STATUS Current state (ACTIVE/FINISHED/FAILED) “FINISHED” PROC_NAME PAL procedure used “PAL_UNIFIED_CLASSIFICATION” 1.2 TRACK_LOG Table The detailed experiment diary capturing chronological events: SELECT * FROM PAL_ML_TRACK.TRACK_LOG WHERE EXECUTION_ID = ‘TRACK_TEST’ORDER BY SEQ, EVENT_TIMESTAMP;Each record includes: EVENT_KEY: Entity type (Parameter/Dataset/Metric) EVENT_MESSAGE: JSON payload with entity details SEQ: Message sequence number Automatic message splitting for payloads > 5000 characters 1.3 TRACK_LOG_HEADER Table The tagging system for log records: SELECT * FROM PAL_ML_TRACK.TRACK_LOG_HEADER WHERE EXECUTION_ID = ‘TRACK_TEST’ORDER BY SEQ;Enables adding custom key-value pairs to any log entry for enhanced categorization. 2. Enabling MLTrack in PAL Procedures Activate tracking by adding these parameters to your PAL call: 2.1 Control Parameters Parameter Type Values Functionality LOG_ML_TRACK INTEGER 0 or 1 Master switch for MLTrack LOG_PARAM INTEGER 0 or 1 Log procedure parameters LOG_DATASET INTEGER 0 or 1 Log dataset metadata LOG_MODEL_SIGNATURE INTEGER 0 or 1 Log model input/output schemas LOG_FIGURE INTEGER 0 or 1 Log visualization data 2.2 Identification Parameters INSERT INTO PAL_PARAMETER_TBL VALUES (‘LOG_ML_TRACK’, 1, NULL, NULL), (‘TRACK_ID’, NULL, NULL, ‘PLAY_PREDICTION_1’), (‘TRACK_DESCRIPTION’, NULL, NULL, ‘Golf play decision tree’), (‘DATASET_NAME’, NULL, NULL, ‘Golf_Play_Dataset’), (‘DATASET_SOURCE’, NULL, NULL, ‘PAL_GOLF_DATA_TBL’);3. Practical Implementation: Classification Example 3.1 Dataset Setup CREATE COLUMN TABLE PAL_GOLF_DATA ( “ID” INTEGER, “OUTLOOK” NVARCHAR(20), “TEMP” DOUBLE, “HUMIDITY” DOUBLE, “WINDY” NVARCHAR(10), “PLAY” NVARCHAR(20) — Target variable);– Sample data insertionINSERT INTO PAL_GOLF_DATA VALUES (1, ‘Sunny’, 75, 70.0, ‘No’, ‘Play’), (2, ‘Rainy’, 68, 80.0, ‘Yes’, ‘Do not Play’);3.2 Parameter Configuration CREATE COLUMN TABLE PAL_PARAMS ( “PARAM_NAME” NVARCHAR(100), “INT_VALUE” INTEGER, “STRING_VALUE” NVARCHAR(100));INSERT INTO PAL_PARAMS VALUES (‘FUNCTION’, NULL, ‘RDT’), — Random Decision Tree (‘MAX_DEPTH’, 10, NULL), (‘LOG_ML_TRACK’, 1, NULL), (‘TRACK_ID’, NULL, ‘GOLF_CLS_EXP_1’), (‘DATASET_SOURCE’, NULL, ‘PAL_GOLF_DATA’);3.3 Execute PAL Procedure with Tracking DOBEGIN lt_data = SELECT * FROM PAL_GOLF_DATA; lt_params = SELECT * FROM PAL_PARAMS; CALL _SYS_AFL.PAL_UNIFIED_CLASSIFICATION_TRACK( :lt_data, :lt_params, lt_model, lt_imp, lt_stat, lt_cmatrix ); — Persist outputs INSERT INTO ML_MODELS SELECT * FROM :lt_model; INSERT INTO FEATURE_IMPORTANCE SELECT * FROM :lt_imp;END;4. Accessing Tracked Experiment Data 4.1 Retrieve Experiment Metadata SELECT * FROM PAL_ML_TRACK.TRACK_METADATA WHERE TRACK_ID = ‘GOLF_CLS_EXP_1’; 4.2 Analyze Logged Parameters SELECT EVENT_MESSAGE FROM PAL_ML_TRACK.TRACK_LOGWHERE EXECUTION_ID = ‘GOLF_CLS_EXP_1’ AND EVENT_KEY = ‘Parameter’; 4.3 Extract Model Evaluation Metrics SELECT EVENT_MESSAGE->>’$.accuracy’ AS accuracy, EVENT_MESSAGE->>’$.f1_score’ AS f1FROM PAL_ML_TRACK.TRACK_LOGWHERE EXECUTION_ID = ‘GOLF_CLS_EXP_1’ AND EVENT_KEY = ‘METRIC’;5. Advanced Management: Log Removal Safely remove experiments using hierarchical deletion: DOBEGIN DECLARE param_tbl TABLE ( PARAM_NAME NVARCHAR(256), STRING_VALUE NVARCHAR(1000) ); DECLARE removed_info TABLE ( TRACK_ID NVARCHAR(128), STATUS NVARCHAR(10) ); INSERT INTO param_tbl VALUES (‘REMOVE_MODE’, ‘1’), — Hierarchical removal (‘TRACK_ID’, ‘GOLF_CLS_EXP_1’), (‘IS_FORCE’, ‘0’); — Don’t remove active tracks CALL _SYS_AFL.PAL_REMOVE_MLTRACK_LOG(:param_tbl, removed_info); SELECT * FROM :removed_info; — Removal confirmationEND; 6. Python Integration with hana_ml HANA ML Experiment Tracking Example This code demonstrates how to track machine learning experiments using SAP HANA ML’s tracking capabilities: 1. Imports and Initialization from hana_ml.artifacts.tracking.tracking import MLExperiments# Create Unified Classification model using Hybrid Gradient Boosting Trees algorithmuc = UnifiedClassification(func=”hybridgradientboostingtree”)2. Experiment Setup # Define unique experiment identifierexperiment_id = “cls_HGBT_0″# Optional: Delete previous experiment logs (commented out)# delete_experiment_log(connection_context, experiment_id)# Initialize experiment tracking objectclass_experiment = MLExperiments( connection_context=connection_context, experiment_id=experiment_id, experiment_description=”cls fit test HGBT”)3. Autologging Configuration # Enable automatic logging for model trainingclass_experiment.autologging( uc, run_name=”diabetes_6″, dataset_name=”diabetes_train”, dataset_source=”DIABETES_TBL”)Key Features Demonstrated: MLExperiments Class: Central class for managing experiment metadata and tracking Autologging: Automatically captures: Model parameters Dataset information Training metadata Experiment Organization: Unique experiment_id groups related runs Custom run_name identifies specific executions Dataset Tracking: Explicit linkage between model runs and training data sources Reference Implementation Details The underlying MLExperiments class provides these core functions: Method Purpose autologging()Attach tracking metadata to models get_current_tracking_id()Retrieve unique ID for the run get_tracking_log_for_current_run()Fetch execution logs get_tracking_metadata_for_current_run()Retrieve metadata 7. Visualization and Monitoring The experiment monitor will display all tracked experiments and experiment runs, obtain the status of each run, and capture detailed internal information about each run. Monitor experiments from hana_ml.visualizers.tracking import ExperimentMonitorexperiment_monitor = ExperimentMonitor(connection_context)experiment_monitor.start() Conclusion MLTrack transforms SAP HANA Cloud into a fully traceable MLOps platform, providing: ✅Reproducibility of any ML experiment ✅Comparability of model versions ✅Auditability for compliance requirements ✅Visualization of experiment history ✅Integration with existing PAL workflows By implementing MLTrack, organizations bridge the gap between experimental machine learning and production-grade MLOps, ensuring every model decision is traceable, explainable, and reproducible. Related Articles:https://community.sap.com/t5/technology-blog-posts-by-sap/new-machine-learning-features-in-sap-hana-cloud-2024-q3/ba-p/13874878https://community.sap.com/t5/artificial-intelligence-and-machine-learning-blogs/hands-on-tutorial-machine-learning-with-sap-hana-cloud/bc-p/14028202#M604https://community.sap.com/t5/technology-blog-posts-by-sap/model-storage-with-python-machine-learning-client-for-sap-hana/ba-p/13483099https://community.sap.com/t5/technology-blog-posts-by-sap/hybrid-prediction-with-tabular-and-text-inputs-using-hybrid-gradient/ba-p/13927218 Read More Technology Blog Posts by SAP articles
#SAP
#SAPTechnologyblog