Introduction:
SAP Datasphere offers multiple options to perform ETL (Extract, Transform & Load) activities. It provides native capabilities to connect to both SAP and non-SAP data sources, extract raw data, perform data transformations, data cleansing, and data load it into target tables. Customers rely on these capabilities to prepare data for building data models or enabling consumption by downstream systems. SAP Datasphere includes several features to support these processes, such as Replication Flow, Transformation Flow, Data Flow, Replicate Remote Table, and Open SQL Procedures (Stored Procedures). While this flexibility is powerful, it also creates the need to clearly understand which approach is recommended, aligns with best practices, and best fits specific business requirements. This article aims to provide clear guidance for data engineers on selecting the right ETL approach, ensuring optimal resource usage, better performance, easier troubleshooting, effective lifecycle management, and alignment with SAP’s future roadmap.
What does Extract, Transform & Load (ETL) mean and Process Steps involved?
ETL (Extract, Transform, Load) is a data integration process used to collect raw data from different sources, prepare it, and make it ready for business use. It ensures that data is clean, consistent, and reliable for reporting, analytics, AI, planning and decision-making.
ETL involves three main steps:
Extract(E): Collect raw data from various sources such as databases, APIs, or filesTransform(T): Clean, validate, conversion, and structure the data (e.g., remove duplicates, apply business rules, standardize formats)Load(L): Store the processed data into a target system like a data warehouse or SAP Datasphere for consumption
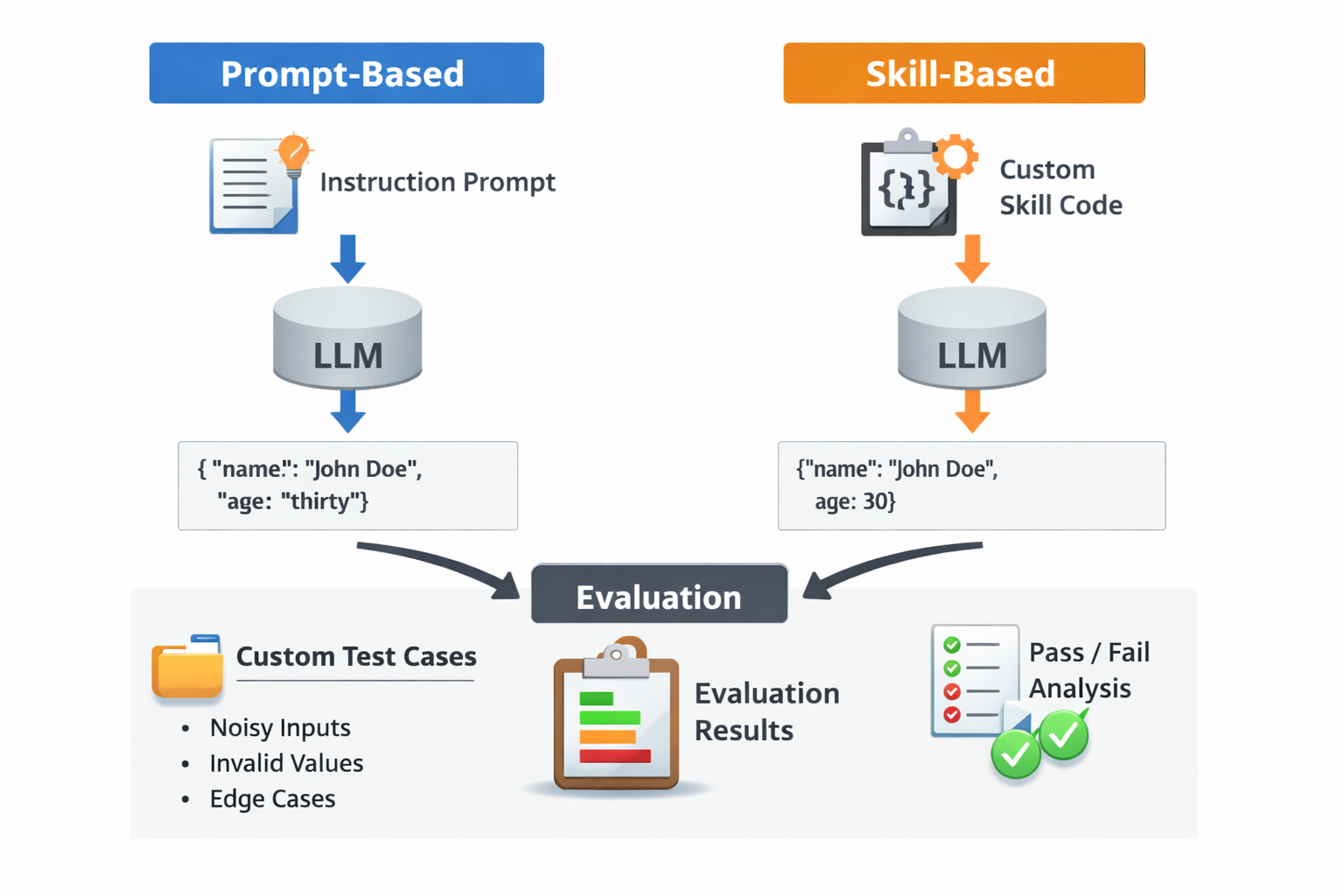
The above diagram illustrates the ETL process from an SAP Datasphere perspective, highlighting the key features that support the Extract, Transform, and Load stages. In addition, SAP Datasphere extends the Load phase with outbound capabilities, enabling data to be written to remote or supported target systems. At the application layer, SAP Datasphere provides features such as Replication Flow, Transformation Flow, Data Flow, and Remote Tables (Snapshot/Replication) to handle ETL processes. At the database layer, it supports advanced processing using Open SQL Procedures (SAP HANA Cloud stored procedures) to handle Transform and Load process.
Do we always need ETL process for SAP business data with the introduction of SAP Business Data Cloud (BDC), Data products?
No, not always. In fact SAP recommends to use and consume, SAP BDC, Data Products if available and meeting business needs as a first-class citizen.
What are the scenarios in SAP Datasphere, where ETL is required?
SAP BDC, SAP Managed Data products are not available for the specific business data set.SAP BDC, Customer Managed Data Products.Preparing data for AI/ML use cases – different staging layers or custom medallion architecture.Non-SAP or External data sources. External CRM/SRM/ERP/HR systems.Sensor/IoT data.Excel/Flat files data.Third-Party applications.Social media data.
What are the different SAP Datasphere features available to support the ETL data operation?
SAP Datasphere, Application Layer Features:
Replication Flow:
It offers high-speed, efficient mass raw data replication/load from supported source systems into supported target systems and It is a cloud-based replication tool in which cloud-to-cloud based replication scenarios does not need middleware components (e.g. SAP Cloud Connector, DP Agent).ETL Process: Supports Extract, Load and Outbound Load (SAP and Non-SAP Targets).Load Types:Supports Initial Only, Delta Only and Initial & Delta load types with change data capture (CDC). Load Frequency: Near real-time, Scheduled (Batch processing) and Manual trigger.Load Targets: SAP Datasphere Local tables, Supported SAP and Non-SAP targets.Features:Mass data replication with initial loads through partition-based parallelization up to a maximum of 16 parallel jobs (80 threads).Runtime/execution setting flexibility to update runtime settings (source and target thread limit, delta load frequency) without redeployment.Available in SAP Datasphere space types: SAP HANA Database (Disk and In-Memory) & SAP HANA Data Lake Files. Email notification for failures at object level.Column projection, mapping and row-level filters available.ABAP Exit: For ABAP systems, Custom complex projection/filter logic is available via BAdi BADI_DHAPE_RMS_EVENTS. Outbound data load (PUSH mechanism): Available for the supported SAP and Non-SAP targets.Use-cases/Business Scenarios:High speed multiple raw data sets replications from a source to a target with support for delta loads.Scenario mainly to perform for data movement, extract and load with minimal or no transformations.Cloud to Cloud replication with need of middleware components like Cloud Connector, DP Agent.Near real-time data ingestion with delta loads e.g. financial transactions, order data, logs etc.Data sync with supported sources and targets.Customer-managed SAP BDC, Data products.Inbound data replication: Replicate data from SAP/Non-SAP sources into SAP Datasphere with change data capture.Outbound data replication: Replicate data from SAP Datasphere into supported SAP and non-SAP outbound targets.Pass-through data replication: Use SAP Datasphere as a middleware ETL tool to replicate data from supported sources into supported targets.
Transformation Flow:
It is a cloud based features to support high-speed data transformations to load data from one or more sources, apply transformations (such as a join/union/conversions), and load result into a target table. ETL Process: Supports Transform and Load.Load Types: Supports Initial Only and Initial & Delta load types with change data capture (CDC). Load Frequency: Scheduled (Batch processing) and Manual trigger.Load Targets: SAP Datasphere Local tables.Features:Graphical and SQL-based transform supported.Transformation capabilities joins, aggregations, functions, calculated columns.Complex data transform, conversion can be achieved using Python custom function. Initial Only works also as a UPSERT (INSERT + UPDATE), Target table has primary keys defined. Existing record gets updated, while new record gets inserted.Delete All Before Loading: Delete all existing records before loading new records capability.Supports input parameter for dynamic execution or filtration.Python script operator for transformation flow in HDLF spaces.Performance analysis via Simulate runs, generate PlanViz files & Generate HANA ExplainPlan.Available in SAP Datasphere space types: SAP HANA Database (Disk and In-Memory) & SAP HANA Data Lake Files. Run mode setting for performance and memory optimized consumption.Use-cases/Business Scenarios:Multi-level data staging layers with complex transformation with delta-staging capabilities.Used in combination with Replication flows for the complete ETL process.Data medallion architecture (Bronze, Silver, Gold) or Customer-managed SAP BDC, Data products.High-speed data transformation compared to Data flows.
Data Flow:
It is a implemented as a single process, running in isolation (in a Kubernetes environment). This process handles the full data pipeline, extracting data from the source, applying transformations, and loading it into the SAP Datasphere, Local tables.Data is processed in chunks, but no state or checkpoints are maintained. As a result, if a failure occurs during execution, the data flow cannot resume from the last processed point and must be restarted from the beginning.ETL Process: Supports Extracts, Transform and Load.Load Types: Supports only initial/full load and no support for delta processing.Load Frequency: Scheduled (Batch processing) and Manual trigger.Load Targets: SAP Datasphere Local tables and Open SQL tables.Features:Graphical UX that provides flexibility and support for SQL transformation (join, union), field-based transformation.Custom logic for transformation using Python script.Operators available – Join, Union, Projection, Aggregation and Script.Create an Input Parameter in a Data Flow.Automatic restart on run failure.Dynamic memory allocation and set expected data volume – Small, Medium, or Large.Load data into Open SQL tables.Use-cases/Business Scenarios:
Use Data Flow when Replication Flow and Transformation Flow do not fully meet your business or data pipeline requirements.Data Flow is ideal for building end-to-end ETL pipelines where you need to combine data from multiple sources, perform complex transformations, including advanced logic using the Python script operator and Blend and enrich data before loading.Design pipelines using remote tables, views, and local tables, apply aggregations and data manipulations, and then load the processed data into SAP Datasphere. It outshines Replication flows in such scenarios. Downsides, restrictions and limitations (Compared to Replication flows Refer KBA: 3512931) It does not support delta loads.The Initialization time for running a data flow takes an average of 20 seconds, causing longer runtime.Performance consideration: Data Flows run as a single, isolated process (Kubernetes pod), handling extraction, transformation, and load in one pipeline.Since Data Flows often interact with external systems over network connections (outside of SAP BTP), performance can vary depending on source system response and network latency.Heavy Python script will slowdown the execution and may runs 40-50 times slower compared to SQL-based options.Scheduling & Startup: Each new Data flow triggers a new execution process (kubernetes pod) typically starting within ~60 seconds. In rare cases, startup may take longer (up to 6 minutes) if additional infrastructure needs to allocated to execute the request.Process fetches data in chunks, but does not keep state snapshots, which means that in case of a processing failure of a data flow, this instance cannot restart from the last processing state.Loading exclusively into SAP Datasphere tables, no outbound target supported.
Comparison: Replication Flows, Transformation Flows and Data Flows.
Remote Table Replication:
By default, remote tables are accessed via federation without data replication. Performance can be improved by replicating data into SAP Datasphere with scheduled or real-time (CDC) updates, allowing seamless switching from remote access to replicated data without changing data models.ETL Process: Supports Extract and Load.Load Types: Supports Replicated (Snapshot/Full-load) and Replicated (Real-Time).Load Frequency: Real-Time,Scheduled (Batch processing), Manual trigger and Paused.Load Targets: SAP Datasphere Local tables.Features:Transparently switch from remote access to snapshots or real-time replication for change data capture (CDC) enabled tables without the need to change the data models.Schedule snapshots for a table via Task chains.Ability to start, stop, pause, resume and cancel real-time replication.Optional partitions to split larger data transfers and execute transactions in parallel.Sorting and Filtering data.Use-cases/Business Scenarios:When there is a need to replicate data into SAP Datasphere for better performance and local processing, Replication Flows are the preferred approach.For scenarios involving remote tables, SAP HANA SDI(via the DP Agent) is recommended, as it enables advanced capabilities like filtering data during load and partitioning for optimized performance.Remote tables are mainly preferred approach for the data federations scenarios.Advantages of using Replication Flow over Remote Table Replication:Cloud-native & low maintenance: No need for on-premise components like DP Agent; Replication Flow uses built-in infrastructure and works seamlessly with cloud sources.Flexible & scalable replication: Supports replication of multiple data assets in a single flow and can target both SAP Datasphere and external systems.Advanced data loading control: Offers customizable Initial + Delta loads with adjustable frequency, unlike fixed real-time replication in remote tables.Better performance optimization: Built-in partitioning and parallel processing with configurable replication threads for faster large data transfers.Robust monitoring & error handling: Provides detailed run metrics and automated retry/recovery mechanisms, reducing manual intervention.
SAP Datasphere, Database Layer Features:
Open SQL Procedure(SAP HANA Cloud Stored Procedure) :
It is a set of powerful database program (SQL statements) saved in the database that runs as a single unit, using SQLScript to execute complex logic and perform both DML operations (like INSERT, UPDATE, DELETE) and DDL structure changes (like CREATE TABLE).ETL Process: Supports Transform and Load.Load Types:Supports only initial/full load and no out-of-the-box delta processing.Load Frequency: Scheduled (Batch processing) and Manual trigger.Load Targets: Open SQL tables.Features:In-memory high performance: Executes logic directly in SAP HANA’s in-memory engine for very fast processing.SQLScript support: Enables advanced logic like loops, conditions, variables, and complex transformations.Parallel processing: Automatically leverages parallelization for handling large datasets efficiently.Support input/output parameters and Enable dynamic, parameter-driven logic (e.g., pass date ranges, filters, runtime conditions).Include and run directly into Task Chains for automated sequencing with other data objects.Use-cases/Business Scenarios:Scenarios requiring row-by-row processing, complex simulations (e.g., Monte Carlo), or dynamic logic that cannot be achieved via Replication flows, Transformation flow or even Data flows.Orchestrating multiple steps (e.g., staging → transform → load in sequence) at Database layer.Data validations, aggregations, and custom processing not easily handled in Datasphere Integration flows.SAP Datasphere, Open SQL schema use cases.
Best practices and Recommendations for Extract, Transform & Load (ETL):
Above, we explored the different SAP Datasphere data integration features, along with their ETL capabilities, use cases, business scenarios, recommendations, and limitations. By now, the best practices should be clear; however, I would like to reiterate which data integration features customers should prioritize when designing and implementing ETL or data pipelines.
1. Consume SAP Business Data Cloud (BDC) Data Products, Whenever Possible: Learn more SAP Business Data Cloud Series. Consume SAP application data exclusively through BDC data products wherever available, as they are pre-modeled, standardized, and aligned with SAP best practices, eliminating the need for custom ETL.
2. Use SAP Datasphere Native Data Integration Capabilities for Extended Scenarios: For cases where SAP BDC data products are unavailable or insufficient, such as non-SAP data integration, SAP BDC customer-managed data products, data marketplace data products, outbound/downstream processing, or custom requirements, use native SAP Datasphere features (Replication Flow, Transformation Flow, Data Flow or Open SQL) to implement ETL efficiently.
3. Use Replication Flow as the FIRST CHOICE for all Extract, Load, and Outbound/Pass-Through scenarios:
Learn more Replication Flow Blog Series.Optimally set Delta Load Frequency based on the data freshness requirements. This setting directly impacts costs as billing is via data integration hours. Longer the schedule lower the costs.Always stop or pause a running replication flow before a source system downtime. For more information, see Working With Existing Replication Flow Runs.When replication flow is stopped or failed for technical reasons (e.g. Datasphere or source system unavailable), it will restart automatically at the point where it failed.3297105 – Important considerations for SAP Datasphere Replication Flows.3483470 – Guideline for Troubleshooting Data and Replication Flows with ABAP Source Systems – SAP Datasphere.Replication Management Service(RMS) known from SAP Data Intelligence and With ABAP Pipeline Engine(APE) when extracting data from ABAP systems, Replication flows are by far more efficient and resilient.3360905 – SAP Data Intelligence / SAP Datasphere – ABAP Integration – Performance when using RMS / Replication FlowsHigh Volume ABAP Data Replications like CDS view I_GLAccountLineItemRawData, Performance optimizations: Configure/increase partitioning via RMS_MAX_PARTITIONS parameter. Partitions are being used by Replication Flows to divide the amount of data to be replicated in smaller chunks, which can then be replicated in parallel depending on the number of assigned replication threads for initial load.One replication object per replication flow for high volume transactional objects.Prefer to have separate/dedicated connection with source for high volume data objects.Adjust the Source Thread Limit and Target Thread Limit instead of default 10.Monitor the state of the buffer table using Tcode DHRDBMON(Tables)/DHCDCMON(CDS views only) /LTRDBMON(SAP ECC).The buffer table is empty / only a few packages are visible from time to time and are immediately set to “In Process”. In case there is still data to process from source side (e.g. as it is still the initial load), this means RMS is retrieving the data from the system faster than the source is pushing data into the buffer.Increase the number of transfer jobs in the respective configuration and for the respective table in transaction LTRC.The buffer table is full. The status of the packages is “Ready”. This means the source is pushing data faster to the buffer than RMS is retrieving the data from it.Try increasing the number of jobs(e.g. 10 to 20) in the respective Replication Flow and set up a dedicated connection for ACDOCA replication purposes only.The buffer table is full. The status of the packages is “In Process”. The source is pushing data and RMS is immediately picking it up. Most likely a higher throughput could be achieved if the buffer size is increased as source and RMS would allow more parallel processing. In transaction DHRDBMON / LTRDBMON, choose the “Expert Function” button. Enter the buffer table name via the F4 help and choose the “Change Settings” radio button. You can freely modify the maximum number of records to be stored in the buffer table and the individual package size. The changed settings will be active immediately. It is recommended not to change the individual package size and to choose a multiple of the package size for the buffer table size. For example, the package size is 51200 records, and the current buffer size is 153600 (three packages). So the new buffer size could be 307200 (six packages).3520040 – Replication flow CDS: execution fails after adding a new field to the table/CDS view – SAP Datasphere.3542106 – How to Re-trigger Failed Partitions in Replication flow.Tools for Troubleshooting. 3470559 – Replication Flows in SAP Datasphere: Outbound Data Volume for Premium Outbound Integration
4. For ETL Data Pipeline, use Replication Flows (EL) + Transformation Flows (T) as a FIRST CHOICE:
KBA: 3512931 SAP recommends using replication flows and transformation flows to realize an ELT approach.Use transformation flows for creating data staging layers, medallion architecture (bronze, silver, gold).Break complex logic into smaller, reusable transformation flows for easier maintenance and troubleshooting.Apply filters and projections early in the flow to reduce data movement and improve performance.Wherever possible, design flows to process incremental (delta) data instead of full loads.Target local table storage can be switched to In-Memory (default: Disk) for best performance for small and high-frequency access tables (e.g. master data, security values, config, etc.)Usage run mode setting for better performance (Performance-Optimized) or optimal memory(Memory-Optimized). Recommended setting is Performance-Optimized.Transformation flow out-of-memory issues: Monitoring and Managing Memory Consumption.3621926 – Memory Error when running Transformation Flow.Simulate Run to test a transformation flow and test desired results. Recommend to use performance analysis option Generate Explain Plan and SQL Analyzer Plan File for optimizations.
5. Use Data flows, ONLY WHEN Replication flows and Transformation flows DO NOT MEET THE REQUIREMENTS:
Informative note while creating a new Dataflow :3709916 – Data flow performance issue: CDS View to SAP Datasphere Local TableUse Replication Flows and Transformation Flows to Load and Write Data.Data Flows do not support delta processing; to load delta data from an external source into SAP Datasphere, use a Replication Flow instead.Apply filters and projections early to reduce data volume and improve performance and Leverage Python Script operator only when necessary; prefer standard operators for better performance.Recommend scheduling Data flow executions at different intervals (staggering) to avoid resource contention and limit concurrent heavy Data flows to prevent resource saturation.Dynamic memory allocation setting should be done only if your data flow run is facing out-of-memory failures.Note: The initialization time for executing a Data Flow typically averages around 20 secs, which can result in longer runtime.
6. Open SQL Procedure (Stored Procedure) as a core database capability when advanced or custom logic is required:
Use Open SQL Procedures for advanced or complex transformations that cannot be achieved using standard Datasphere features (Replication/Transformation Flows).Use task chain to run and schedule Open SQL procedures.Push Down Logic to Database: Leverage in-database processing (HANA Cloud) for high-performance data transformations and large-volume processing.Use input parameters, data filters, selective columns, optimal SQL functions for the best performance. Break procedures into smaller, reusable components to improve maintainability and readability.Optimize Performance: Use set-based operations instead of row-by-row processing, avoid unnecessary loops, cursors and Ensure proper indexing and efficient joins.
Performance Test Results:
Note / Disclaimer: The tests below were conducted on internal test tenants with minimal sizing and low load on both the source systems and SAP Datasphere. Actual results may vary depending on factors such as tenant size, system load, and configuration. These results are intended to provide a technical comparison of how different features perform from an ETL perspective.
1. Replication Flow vs Data Flow.
Business scenario: A company want to extract & load the PO historical data via CDS view: C_PURCHASEORDERHISTORYDEX having 600K records with 78 columns with no transformation.This is a one-time data load.
Replication Flow with default setting, runtime: 00:02:04
Data Flow with default setting, runtime: 00:05:46
2. Transformation Flow vs Data Flow.
Business scenario: A company needs to transform a SAP Datasphere local table (master data) containing 100K records by adding a new validity column with the current date (TO_VARCHAR(CURRENT_DATE(),’YYYY/MM/DD’)).
Transformation Flow with default setting, runtime: 00:00:02Data Flow with default setting, runtime: 00:01:22
3. Transformation Flow vs Open SQL Procedure.
Business scenario: A company needs to identify Open vs Closed Purchase Orders (POs) by comparing ordered vs delivered quantities, and update the PO history table. The table contains 600K records with 78 existing columns, and requires adding 2 new columns (PO_STATUS and UPDATE_DATE) using transformation logic.
Transformation Flow with default setting, runtime: 00:00:11Open SQL Procedure, called via Task Chain, total runtime: 00:00:52 (SQL Script Procedure runtime 00:00:03)
Reference SQL Code:
/*Grant access to Datasphere space*/
CALL “DWC_GLOBAL”.”GRANT_PRIVILEGE_TO_SPACE” (
OPERATION => ‘GRANT’,
PRIVILEGE => ”, /*INSERT,UPDATE,DELETE */
SCHEMA_NAME => ‘WORKSHOP_ADMIN#JEET’,
OBJECT_NAME => ‘C_PURCHASEORDERHISTORYDEX_HDB’,
SPACE_ID => ‘WORKSHOP_ADMIN’);
/*Grant access to Datasphere space*/
CALL “DWC_GLOBAL”.”GRANT_PRIVILEGE_TO_SPACE” (
OPERATION => ‘GRANT’,
PRIVILEGE => ‘EXECUTE’,
SCHEMA_NAME => ‘WORKSHOP_ADMIN#JEET’,
OBJECT_NAME => ‘SP_PERFORM_TEST3’,
SPACE_ID => ‘WORKSHOP_ADMIN’);
/*Open SQL Procedure Code*/
CREATE OR REPLACE PROCEDURE “WORKSHOP_ADMIN#JEET”.”SP_PERFORM_TEST3″
(
IN P_SCHEMA NVARCHAR(256) DEFAULT ‘WORKSHOP_ADMIN#JEET’
)
LANGUAGE SQLSCRIPT
SQL SECURITY INVOKER
DEFAULT SCHEMA WORKSHOP_ADMIN#JEET
AS
BEGIN SEQUENTIAL EXECUTION
— Perform set-based update for optimal performance
UPDATE “WORKSHOP_ADMIN#JEET”.”C_PURCHASEORDERHISTORYDEX_HDB”
SET
“PO_STATUS” =
CASE
WHEN “DeliveredQty” < “OrderedQty” THEN ‘OPEN’
ELSE ‘CLOSED’
END,
“UPDATE_DATE” = TO_VARCHAR(CURRENT_DATE, ‘MM/DD/YYYY’);
END;
Based on the performance testing comparison above:
Extract & Load scenario: Replication Flow performs faster than Data Flow.Transform scenario: Transformation Flow performs better than Data Flow.Transform scenario (Application vs. Database layer): Open SQL Procedures (database layer) outperform Transformation Flows.
Conclusion:
SAP Datasphere provides a rich and flexible set of ETL capabilities, but choosing the right approach is critical for achieving optimal performance and scalability. As demonstrated, Replication Flows and Transformation Flows should be the primary choice for most ELT scenarios, offering efficiency, scalability, and alignment with SAP’s recommended architecture. Data Flows should be used selectively, only when specific requirements cannot be met by the preferred options. For advanced transformations and high-performance processing, Open SQL Procedures at the database layer provide significant advantages. Additionally, whenever possible, leveraging SAP Business Data Cloud (BDC) data products can eliminate the need for custom ETL altogether. By aligning design decisions with these best practices, organizations can build robust, efficient, and future-ready data pipelines in SAP Datasphere.
References:
https://help.sap.com/docs/SAP_DATASPHERE https://community.sap.com/t5/technology-blog-posts-by-sap/replication-flow-blog-series-part-1-overview/ba-p/13581472 https://community.sap.com/t5/technology-blog-posts-by-sap/sap-datasphere-space-data-integration-and-data-modeling-best-practices/ba-p/13651889 https://pages.community.sap.com/topics/datasphere/best-practices-troubleshooting https://help.sap.com/docs/SUPPORT_CONTENT/datasphere/4428871866.html
Happy Learning!😊
Introduction:SAP Datasphere offers multiple options to perform ETL (Extract, Transform & Load) activities. It provides native capabilities to connect to both SAP and non-SAP data sources, extract raw data, perform data transformations, data cleansing, and data load it into target tables. Customers rely on these capabilities to prepare data for building data models or enabling consumption by downstream systems. SAP Datasphere includes several features to support these processes, such as Replication Flow, Transformation Flow, Data Flow, Replicate Remote Table, and Open SQL Procedures (Stored Procedures). While this flexibility is powerful, it also creates the need to clearly understand which approach is recommended, aligns with best practices, and best fits specific business requirements. This article aims to provide clear guidance for data engineers on selecting the right ETL approach, ensuring optimal resource usage, better performance, easier troubleshooting, effective lifecycle management, and alignment with SAP’s future roadmap.What does Extract, Transform & Load (ETL) mean and Process Steps involved? ETL (Extract, Transform, Load) is a data integration process used to collect raw data from different sources, prepare it, and make it ready for business use. It ensures that data is clean, consistent, and reliable for reporting, analytics, AI, planning and decision-making.ETL involves three main steps:Extract(E): Collect raw data from various sources such as databases, APIs, or filesTransform(T): Clean, validate, conversion, and structure the data (e.g., remove duplicates, apply business rules, standardize formats)Load(L): Store the processed data into a target system like a data warehouse or SAP Datasphere for consumptionThe above diagram illustrates the ETL process from an SAP Datasphere perspective, highlighting the key features that support the Extract, Transform, and Load stages. In addition, SAP Datasphere extends the Load phase with outbound capabilities, enabling data to be written to remote or supported target systems. At the application layer, SAP Datasphere provides features such as Replication Flow, Transformation Flow, Data Flow, and Remote Tables (Snapshot/Replication) to handle ETL processes. At the database layer, it supports advanced processing using Open SQL Procedures (SAP HANA Cloud stored procedures) to handle Transform and Load process.Do we always need ETL process for SAP business data with the introduction of SAP Business Data Cloud (BDC), Data products?No, not always. In fact SAP recommends to use and consume, SAP BDC, Data Products if available and meeting business needs as a first-class citizen. What are the scenarios in SAP Datasphere, where ETL is required?SAP BDC, SAP Managed Data products are not available for the specific business data set.SAP BDC, Customer Managed Data Products.Preparing data for AI/ML use cases – different staging layers or custom medallion architecture.Non-SAP or External data sources. External CRM/SRM/ERP/HR systems.Sensor/IoT data.Excel/Flat files data.Third-Party applications.Social media data.What are the different SAP Datasphere features available to support the ETL data operation?SAP Datasphere, Application Layer Features:Replication Flow: It offers high-speed, efficient mass raw data replication/load from supported source systems into supported target systems and It is a cloud-based replication tool in which cloud-to-cloud based replication scenarios does not need middleware components (e.g. SAP Cloud Connector, DP Agent).ETL Process: Supports Extract, Load and Outbound Load (SAP and Non-SAP Targets).Load Types:Supports Initial Only, Delta Only and Initial & Delta load types with change data capture (CDC). Load Frequency: Near real-time, Scheduled (Batch processing) and Manual trigger.Load Targets: SAP Datasphere Local tables, Supported SAP and Non-SAP targets.Features:Mass data replication with initial loads through partition-based parallelization up to a maximum of 16 parallel jobs (80 threads).Runtime/execution setting flexibility to update runtime settings (source and target thread limit, delta load frequency) without redeployment.Available in SAP Datasphere space types: SAP HANA Database (Disk and In-Memory) & SAP HANA Data Lake Files. Email notification for failures at object level.Column projection, mapping and row-level filters available.ABAP Exit: For ABAP systems, Custom complex projection/filter logic is available via BAdi BADI_DHAPE_RMS_EVENTS. Outbound data load (PUSH mechanism): Available for the supported SAP and Non-SAP targets.Use-cases/Business Scenarios:High speed multiple raw data sets replications from a source to a target with support for delta loads.Scenario mainly to perform for data movement, extract and load with minimal or no transformations.Cloud to Cloud replication with need of middleware components like Cloud Connector, DP Agent.Near real-time data ingestion with delta loads e.g. financial transactions, order data, logs etc.Data sync with supported sources and targets.Customer-managed SAP BDC, Data products.Inbound data replication: Replicate data from SAP/Non-SAP sources into SAP Datasphere with change data capture.Outbound data replication: Replicate data from SAP Datasphere into supported SAP and non-SAP outbound targets.Pass-through data replication: Use SAP Datasphere as a middleware ETL tool to replicate data from supported sources into supported targets. Transformation Flow: It is a cloud based features to support high-speed data transformations to load data from one or more sources, apply transformations (such as a join/union/conversions), and load result into a target table. ETL Process: Supports Transform and Load.Load Types: Supports Initial Only and Initial & Delta load types with change data capture (CDC). Load Frequency: Scheduled (Batch processing) and Manual trigger.Load Targets: SAP Datasphere Local tables.Features:Graphical and SQL-based transform supported.Transformation capabilities joins, aggregations, functions, calculated columns.Complex data transform, conversion can be achieved using Python custom function. Initial Only works also as a UPSERT (INSERT + UPDATE), Target table has primary keys defined. Existing record gets updated, while new record gets inserted.Delete All Before Loading: Delete all existing records before loading new records capability.Supports input parameter for dynamic execution or filtration.Python script operator for transformation flow in HDLF spaces.Performance analysis via Simulate runs, generate PlanViz files & Generate HANA ExplainPlan.Available in SAP Datasphere space types: SAP HANA Database (Disk and In-Memory) & SAP HANA Data Lake Files. Run mode setting for performance and memory optimized consumption.Use-cases/Business Scenarios:Multi-level data staging layers with complex transformation with delta-staging capabilities.Used in combination with Replication flows for the complete ETL process.Data medallion architecture (Bronze, Silver, Gold) or Customer-managed SAP BDC, Data products.High-speed data transformation compared to Data flows. Data Flow: It is a implemented as a single process, running in isolation (in a Kubernetes environment). This process handles the full data pipeline, extracting data from the source, applying transformations, and loading it into the SAP Datasphere, Local tables.Data is processed in chunks, but no state or checkpoints are maintained. As a result, if a failure occurs during execution, the data flow cannot resume from the last processed point and must be restarted from the beginning.ETL Process: Supports Extracts, Transform and Load.Load Types: Supports only initial/full load and no support for delta processing.Load Frequency: Scheduled (Batch processing) and Manual trigger.Load Targets: SAP Datasphere Local tables and Open SQL tables.Features:Graphical UX that provides flexibility and support for SQL transformation (join, union), field-based transformation.Custom logic for transformation using Python script.Operators available – Join, Union, Projection, Aggregation and Script.Create an Input Parameter in a Data Flow.Automatic restart on run failure.Dynamic memory allocation and set expected data volume – Small, Medium, or Large.Load data into Open SQL tables.Use-cases/Business Scenarios:Use Data Flow when Replication Flow and Transformation Flow do not fully meet your business or data pipeline requirements.Data Flow is ideal for building end-to-end ETL pipelines where you need to combine data from multiple sources, perform complex transformations, including advanced logic using the Python script operator and Blend and enrich data before loading.Design pipelines using remote tables, views, and local tables, apply aggregations and data manipulations, and then load the processed data into SAP Datasphere. It outshines Replication flows in such scenarios. Downsides, restrictions and limitations (Compared to Replication flows Refer KBA: 3512931) It does not support delta loads.The Initialization time for running a data flow takes an average of 20 seconds, causing longer runtime.Performance consideration: Data Flows run as a single, isolated process (Kubernetes pod), handling extraction, transformation, and load in one pipeline.Since Data Flows often interact with external systems over network connections (outside of SAP BTP), performance can vary depending on source system response and network latency.Heavy Python script will slowdown the execution and may runs 40-50 times slower compared to SQL-based options.Scheduling & Startup: Each new Data flow triggers a new execution process (kubernetes pod) typically starting within ~60 seconds. In rare cases, startup may take longer (up to 6 minutes) if additional infrastructure needs to allocated to execute the request.Process fetches data in chunks, but does not keep state snapshots, which means that in case of a processing failure of a data flow, this instance cannot restart from the last processing state.Loading exclusively into SAP Datasphere tables, no outbound target supported. Comparison: Replication Flows, Transformation Flows and Data Flows. Remote Table Replication: By default, remote tables are accessed via federation without data replication. Performance can be improved by replicating data into SAP Datasphere with scheduled or real-time (CDC) updates, allowing seamless switching from remote access to replicated data without changing data models.ETL Process: Supports Extract and Load.Load Types: Supports Replicated (Snapshot/Full-load) and Replicated (Real-Time).Load Frequency: Real-Time,Scheduled (Batch processing), Manual trigger and Paused.Load Targets: SAP Datasphere Local tables.Features:Transparently switch from remote access to snapshots or real-time replication for change data capture (CDC) enabled tables without the need to change the data models.Schedule snapshots for a table via Task chains.Ability to start, stop, pause, resume and cancel real-time replication.Optional partitions to split larger data transfers and execute transactions in parallel.Sorting and Filtering data.Use-cases/Business Scenarios:When there is a need to replicate data into SAP Datasphere for better performance and local processing, Replication Flows are the preferred approach.For scenarios involving remote tables, SAP HANA SDI(via the DP Agent) is recommended, as it enables advanced capabilities like filtering data during load and partitioning for optimized performance.Remote tables are mainly preferred approach for the data federations scenarios.Advantages of using Replication Flow over Remote Table Replication:Cloud-native & low maintenance: No need for on-premise components like DP Agent; Replication Flow uses built-in infrastructure and works seamlessly with cloud sources.Flexible & scalable replication: Supports replication of multiple data assets in a single flow and can target both SAP Datasphere and external systems.Advanced data loading control: Offers customizable Initial + Delta loads with adjustable frequency, unlike fixed real-time replication in remote tables.Better performance optimization: Built-in partitioning and parallel processing with configurable replication threads for faster large data transfers.Robust monitoring & error handling: Provides detailed run metrics and automated retry/recovery mechanisms, reducing manual intervention. SAP Datasphere, Database Layer Features:Open SQL Procedure(SAP HANA Cloud Stored Procedure) :It is a set of powerful database program (SQL statements) saved in the database that runs as a single unit, using SQLScript to execute complex logic and perform both DML operations (like INSERT, UPDATE, DELETE) and DDL structure changes (like CREATE TABLE).ETL Process: Supports Transform and Load.Load Types:Supports only initial/full load and no out-of-the-box delta processing.Load Frequency: Scheduled (Batch processing) and Manual trigger.Load Targets: Open SQL tables.Features:In-memory high performance: Executes logic directly in SAP HANA’s in-memory engine for very fast processing.SQLScript support: Enables advanced logic like loops, conditions, variables, and complex transformations.Parallel processing: Automatically leverages parallelization for handling large datasets efficiently.Support input/output parameters and Enable dynamic, parameter-driven logic (e.g., pass date ranges, filters, runtime conditions).Include and run directly into Task Chains for automated sequencing with other data objects.Use-cases/Business Scenarios:Scenarios requiring row-by-row processing, complex simulations (e.g., Monte Carlo), or dynamic logic that cannot be achieved via Replication flows, Transformation flow or even Data flows.Orchestrating multiple steps (e.g., staging → transform → load in sequence) at Database layer.Data validations, aggregations, and custom processing not easily handled in Datasphere Integration flows.SAP Datasphere, Open SQL schema use cases. Best practices and Recommendations for Extract, Transform & Load (ETL): Above, we explored the different SAP Datasphere data integration features, along with their ETL capabilities, use cases, business scenarios, recommendations, and limitations. By now, the best practices should be clear; however, I would like to reiterate which data integration features customers should prioritize when designing and implementing ETL or data pipelines.1. Consume SAP Business Data Cloud (BDC) Data Products, Whenever Possible: Learn more SAP Business Data Cloud Series. Consume SAP application data exclusively through BDC data products wherever available, as they are pre-modeled, standardized, and aligned with SAP best practices, eliminating the need for custom ETL.2. Use SAP Datasphere Native Data Integration Capabilities for Extended Scenarios: For cases where SAP BDC data products are unavailable or insufficient, such as non-SAP data integration, SAP BDC customer-managed data products, data marketplace data products, outbound/downstream processing, or custom requirements, use native SAP Datasphere features (Replication Flow, Transformation Flow, Data Flow or Open SQL) to implement ETL efficiently.3. Use Replication Flow as the FIRST CHOICE for all Extract, Load, and Outbound/Pass-Through scenarios: Learn more Replication Flow Blog Series.Optimally set Delta Load Frequency based on the data freshness requirements. This setting directly impacts costs as billing is via data integration hours. Longer the schedule lower the costs.Always stop or pause a running replication flow before a source system downtime. For more information, see Working With Existing Replication Flow Runs.When replication flow is stopped or failed for technical reasons (e.g. Datasphere or source system unavailable), it will restart automatically at the point where it failed.3297105 – Important considerations for SAP Datasphere Replication Flows.3483470 – Guideline for Troubleshooting Data and Replication Flows with ABAP Source Systems – SAP Datasphere.Replication Management Service(RMS) known from SAP Data Intelligence and With ABAP Pipeline Engine(APE) when extracting data from ABAP systems, Replication flows are by far more efficient and resilient.3360905 – SAP Data Intelligence / SAP Datasphere – ABAP Integration – Performance when using RMS / Replication FlowsHigh Volume ABAP Data Replications like CDS view I_GLAccountLineItemRawData, Performance optimizations: Configure/increase partitioning via RMS_MAX_PARTITIONS parameter. Partitions are being used by Replication Flows to divide the amount of data to be replicated in smaller chunks, which can then be replicated in parallel depending on the number of assigned replication threads for initial load.One replication object per replication flow for high volume transactional objects.Prefer to have separate/dedicated connection with source for high volume data objects.Adjust the Source Thread Limit and Target Thread Limit instead of default 10.Monitor the state of the buffer table using Tcode DHRDBMON(Tables)/DHCDCMON(CDS views only) /LTRDBMON(SAP ECC).The buffer table is empty / only a few packages are visible from time to time and are immediately set to “In Process”. In case there is still data to process from source side (e.g. as it is still the initial load), this means RMS is retrieving the data from the system faster than the source is pushing data into the buffer.Increase the number of transfer jobs in the respective configuration and for the respective table in transaction LTRC.The buffer table is full. The status of the packages is “Ready”. This means the source is pushing data faster to the buffer than RMS is retrieving the data from it.Try increasing the number of jobs(e.g. 10 to 20) in the respective Replication Flow and set up a dedicated connection for ACDOCA replication purposes only.The buffer table is full. The status of the packages is “In Process”. The source is pushing data and RMS is immediately picking it up. Most likely a higher throughput could be achieved if the buffer size is increased as source and RMS would allow more parallel processing. In transaction DHRDBMON / LTRDBMON, choose the “Expert Function” button. Enter the buffer table name via the F4 help and choose the “Change Settings” radio button. You can freely modify the maximum number of records to be stored in the buffer table and the individual package size. The changed settings will be active immediately. It is recommended not to change the individual package size and to choose a multiple of the package size for the buffer table size. For example, the package size is 51200 records, and the current buffer size is 153600 (three packages). So the new buffer size could be 307200 (six packages).3520040 – Replication flow CDS: execution fails after adding a new field to the table/CDS view – SAP Datasphere.3542106 – How to Re-trigger Failed Partitions in Replication flow.Tools for Troubleshooting. 3470559 – Replication Flows in SAP Datasphere: Outbound Data Volume for Premium Outbound Integration4. For ETL Data Pipeline, use Replication Flows (EL) + Transformation Flows (T) as a FIRST CHOICE:KBA: 3512931 SAP recommends using replication flows and transformation flows to realize an ELT approach.Use transformation flows for creating data staging layers, medallion architecture (bronze, silver, gold).Break complex logic into smaller, reusable transformation flows for easier maintenance and troubleshooting.Apply filters and projections early in the flow to reduce data movement and improve performance.Wherever possible, design flows to process incremental (delta) data instead of full loads.Target local table storage can be switched to In-Memory (default: Disk) for best performance for small and high-frequency access tables (e.g. master data, security values, config, etc.)Usage run mode setting for better performance (Performance-Optimized) or optimal memory(Memory-Optimized). Recommended setting is Performance-Optimized.Transformation flow out-of-memory issues: Monitoring and Managing Memory Consumption.3621926 – Memory Error when running Transformation Flow.Simulate Run to test a transformation flow and test desired results. Recommend to use performance analysis option Generate Explain Plan and SQL Analyzer Plan File for optimizations.5. Use Data flows, ONLY WHEN Replication flows and Transformation flows DO NOT MEET THE REQUIREMENTS:Informative note while creating a new Dataflow :3709916 – Data flow performance issue: CDS View to SAP Datasphere Local TableUse Replication Flows and Transformation Flows to Load and Write Data.Data Flows do not support delta processing; to load delta data from an external source into SAP Datasphere, use a Replication Flow instead.Apply filters and projections early to reduce data volume and improve performance and Leverage Python Script operator only when necessary; prefer standard operators for better performance.Recommend scheduling Data flow executions at different intervals (staggering) to avoid resource contention and limit concurrent heavy Data flows to prevent resource saturation.Dynamic memory allocation setting should be done only if your data flow run is facing out-of-memory failures.Note: The initialization time for executing a Data Flow typically averages around 20 secs, which can result in longer runtime.6. Open SQL Procedure (Stored Procedure) as a core database capability when advanced or custom logic is required:Use Open SQL Procedures for advanced or complex transformations that cannot be achieved using standard Datasphere features (Replication/Transformation Flows).Use task chain to run and schedule Open SQL procedures.Push Down Logic to Database: Leverage in-database processing (HANA Cloud) for high-performance data transformations and large-volume processing.Use input parameters, data filters, selective columns, optimal SQL functions for the best performance. Break procedures into smaller, reusable components to improve maintainability and readability.Optimize Performance: Use set-based operations instead of row-by-row processing, avoid unnecessary loops, cursors and Ensure proper indexing and efficient joins.Performance Test Results:Note / Disclaimer: The tests below were conducted on internal test tenants with minimal sizing and low load on both the source systems and SAP Datasphere. Actual results may vary depending on factors such as tenant size, system load, and configuration. These results are intended to provide a technical comparison of how different features perform from an ETL perspective. 1. Replication Flow vs Data Flow.Business scenario: A company want to extract & load the PO historical data via CDS view: C_PURCHASEORDERHISTORYDEX having 600K records with 78 columns with no transformation.This is a one-time data load.Replication Flow with default setting, runtime: 00:02:04Data Flow with default setting, runtime: 00:05:46 2. Transformation Flow vs Data Flow.Business scenario: A company needs to transform a SAP Datasphere local table (master data) containing 100K records by adding a new validity column with the current date (TO_VARCHAR(CURRENT_DATE(),’YYYY/MM/DD’)). Transformation Flow with default setting, runtime: 00:00:02Data Flow with default setting, runtime: 00:01:22 3. Transformation Flow vs Open SQL Procedure.Business scenario: A company needs to identify Open vs Closed Purchase Orders (POs) by comparing ordered vs delivered quantities, and update the PO history table. The table contains 600K records with 78 existing columns, and requires adding 2 new columns (PO_STATUS and UPDATE_DATE) using transformation logic.Transformation Flow with default setting, runtime: 00:00:11Open SQL Procedure, called via Task Chain, total runtime: 00:00:52 (SQL Script Procedure runtime 00:00:03) Reference SQL Code:/*Grant access to Datasphere space*/
CALL “DWC_GLOBAL”.”GRANT_PRIVILEGE_TO_SPACE” (
OPERATION => ‘GRANT’,
PRIVILEGE => ”, /*INSERT,UPDATE,DELETE */
SCHEMA_NAME => ‘WORKSHOP_ADMIN#JEET’,
OBJECT_NAME => ‘C_PURCHASEORDERHISTORYDEX_HDB’,
SPACE_ID => ‘WORKSHOP_ADMIN’);
/*Grant access to Datasphere space*/
CALL “DWC_GLOBAL”.”GRANT_PRIVILEGE_TO_SPACE” (
OPERATION => ‘GRANT’,
PRIVILEGE => ‘EXECUTE’,
SCHEMA_NAME => ‘WORKSHOP_ADMIN#JEET’,
OBJECT_NAME => ‘SP_PERFORM_TEST3’,
SPACE_ID => ‘WORKSHOP_ADMIN’);
/*Open SQL Procedure Code*/
CREATE OR REPLACE PROCEDURE “WORKSHOP_ADMIN#JEET”.”SP_PERFORM_TEST3″
(
IN P_SCHEMA NVARCHAR(256) DEFAULT ‘WORKSHOP_ADMIN#JEET’
)
LANGUAGE SQLSCRIPT
SQL SECURITY INVOKER
DEFAULT SCHEMA WORKSHOP_ADMIN#JEET
AS
BEGIN SEQUENTIAL EXECUTION
— Perform set-based update for optimal performance
UPDATE “WORKSHOP_ADMIN#JEET”.”C_PURCHASEORDERHISTORYDEX_HDB”
SET
“PO_STATUS” =
CASE
WHEN “DeliveredQty” < “OrderedQty” THEN ‘OPEN’
ELSE ‘CLOSED’
END,
“UPDATE_DATE” = TO_VARCHAR(CURRENT_DATE, ‘MM/DD/YYYY’);
END;Based on the performance testing comparison above:Extract & Load scenario: Replication Flow performs faster than Data Flow.Transform scenario: Transformation Flow performs better than Data Flow.Transform scenario (Application vs. Database layer): Open SQL Procedures (database layer) outperform Transformation Flows.Conclusion:SAP Datasphere provides a rich and flexible set of ETL capabilities, but choosing the right approach is critical for achieving optimal performance and scalability. As demonstrated, Replication Flows and Transformation Flows should be the primary choice for most ELT scenarios, offering efficiency, scalability, and alignment with SAP’s recommended architecture. Data Flows should be used selectively, only when specific requirements cannot be met by the preferred options. For advanced transformations and high-performance processing, Open SQL Procedures at the database layer provide significant advantages. Additionally, whenever possible, leveraging SAP Business Data Cloud (BDC) data products can eliminate the need for custom ETL altogether. By aligning design decisions with these best practices, organizations can build robust, efficient, and future-ready data pipelines in SAP Datasphere.References:https://help.sap.com/docs/SAP_DATASPHERE https://community.sap.com/t5/technology-blog-posts-by-sap/replication-flow-blog-series-part-1-overview/ba-p/13581472 https://community.sap.com/t5/technology-blog-posts-by-sap/sap-datasphere-space-data-integration-and-data-modeling-best-practices/ba-p/13651889 https://pages.community.sap.com/topics/datasphere/best-practices-troubleshooting https://help.sap.com/docs/SUPPORT_CONTENT/datasphere/4428871866.html Happy Learning!😊 Read More Technology Blog Posts by SAP articles
#SAP
#SAPTechnologyblog