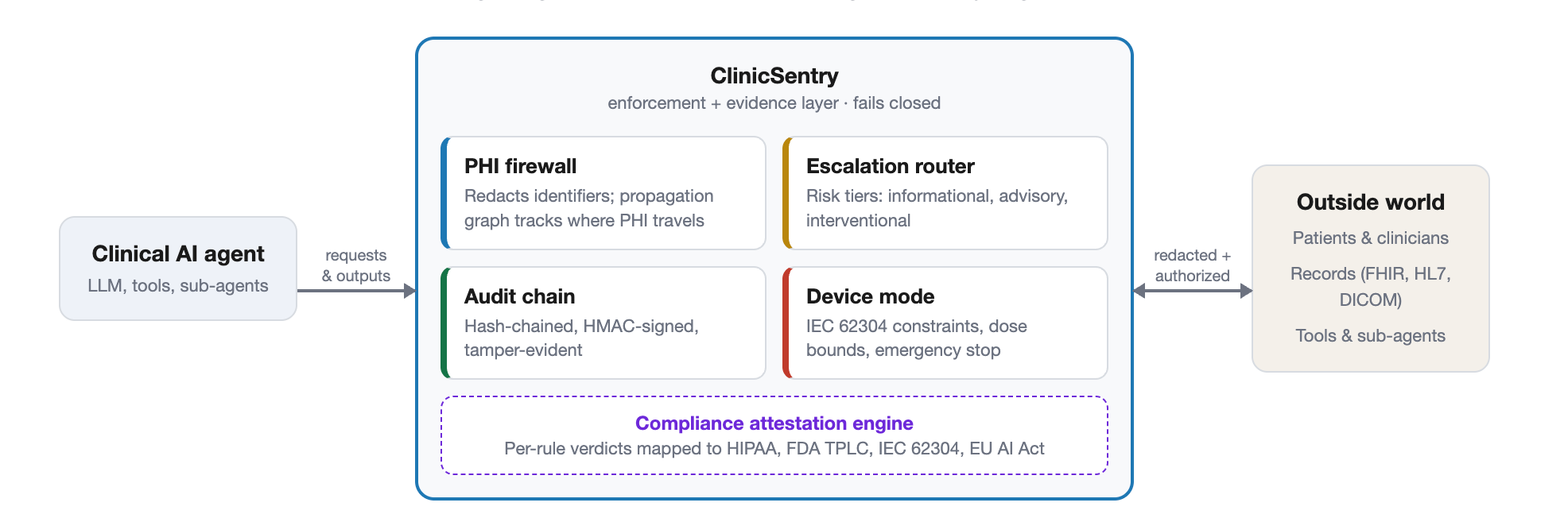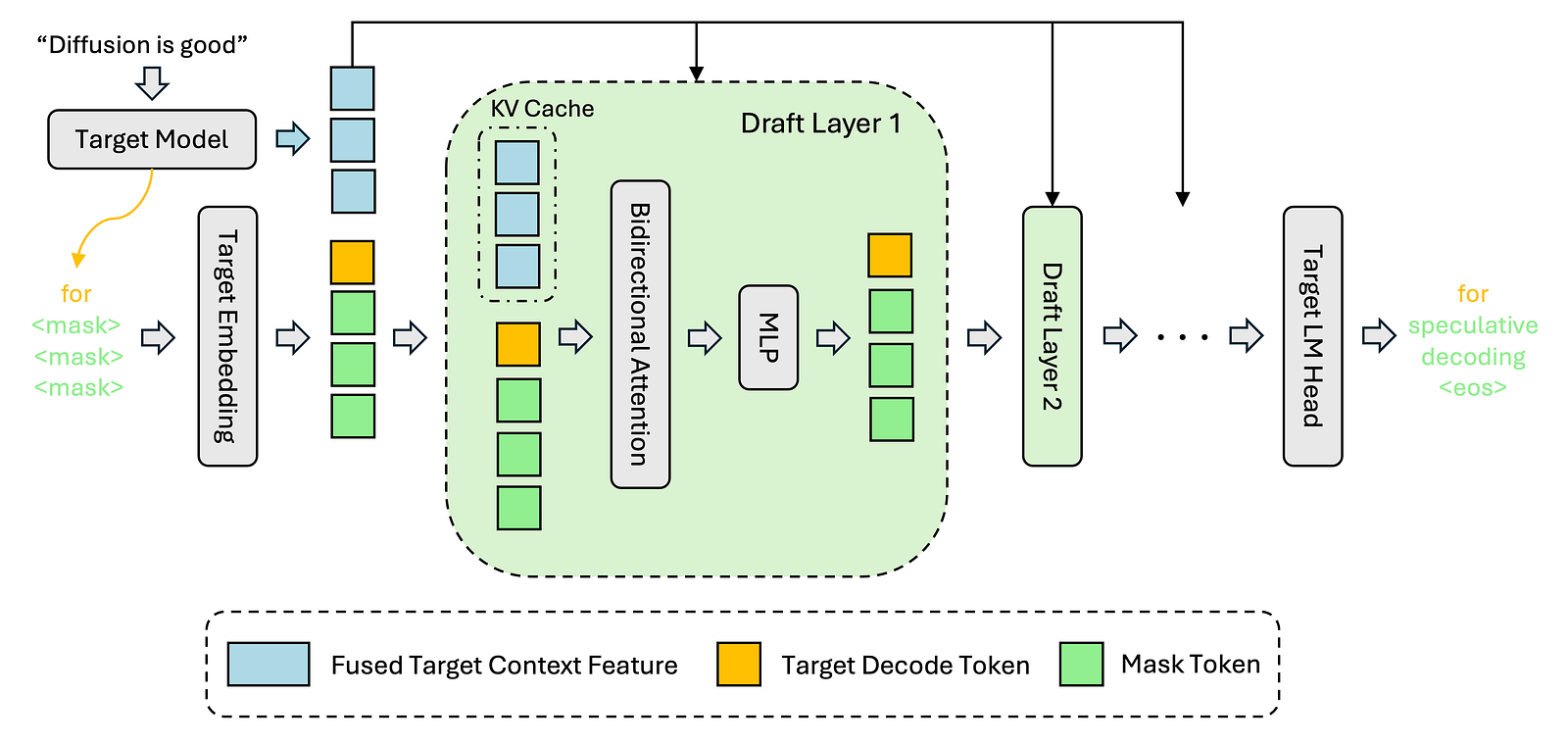
I benchmarked three implementations, and learned something useful about why long-context speculative decoding is actually slower…
I benchmarked three implementations, and learned something useful about why long-context speculative decoding is actually slower…Continue reading on Medium » Read More LLM on Medium
#AI