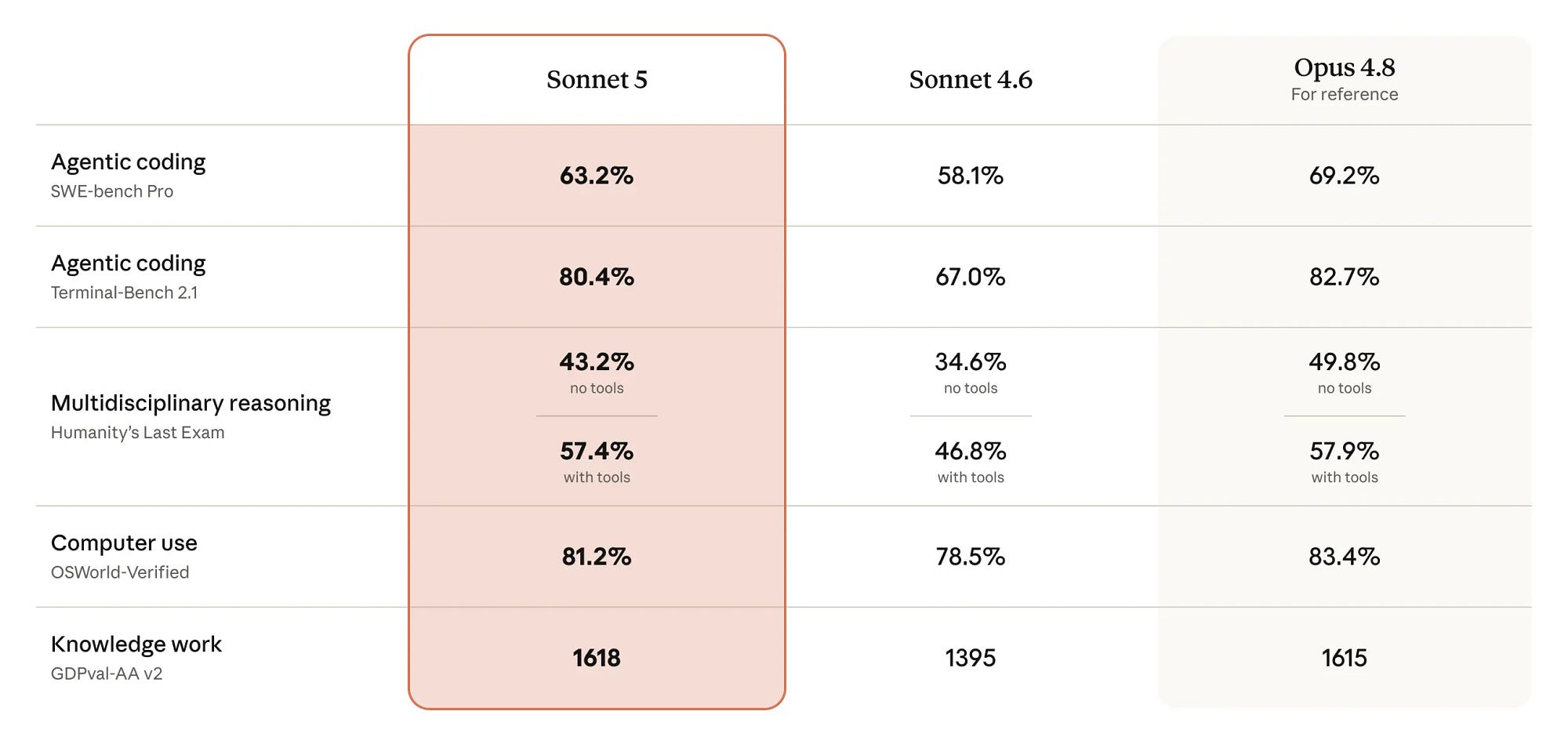
When discussing the quality of a language model, we usually talk about parameter count, training data, or benchmark scores. These are, of…
When discussing the quality of a language model, we usually talk about parameter count, training data, or benchmark scores. These are, of…Continue reading on Medium » Read More LLM on Medium
#AI