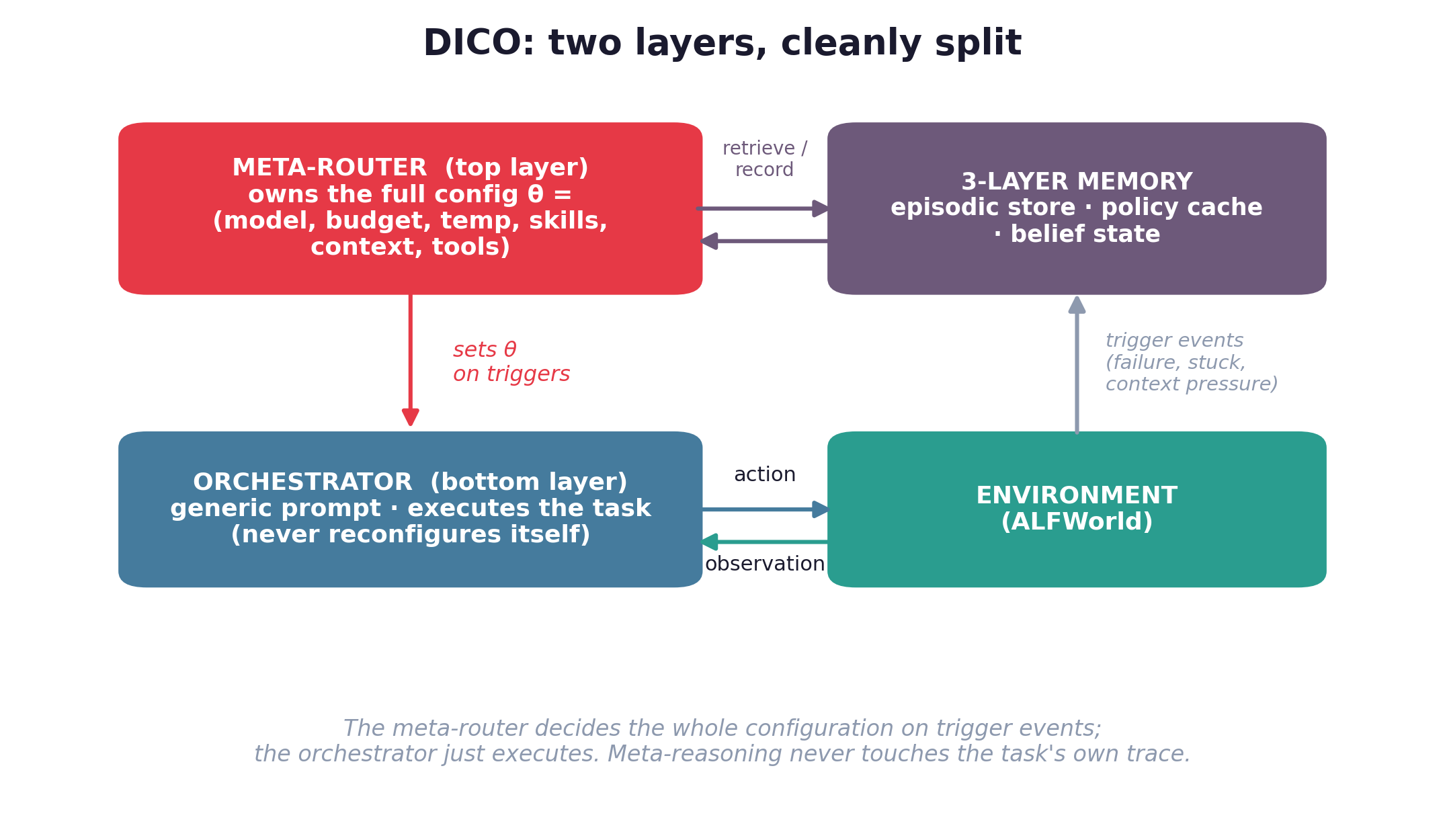
This blog is part of a blog series from SAP Datasphere product management with the focus on the Replication Flow capabilities in SAP Datasphere:
Replication Flow Blog Series Part 1 – Overview | SAP Blogs
Replication Flow Blog Series Part 2 – Premium Outbound Integration | SAP Blogs
Replication Flows Blog Series Part 3 – Integration with Kafka
Replication Flows Blog Series Part 4 – Sizing
Replication Flows Blog Series Part 5 – Integration between SAP Datasphere and Databricks
Replication Flows Blog Series Part 6 – Confluent as a Replication Target
Replication Flows Blog Series Part 7 – Performance
Replication Flows Blog Series Part 8 – Confluent as a Replication Source
Data Integration is an essential topic in a Business Data Fabric like SAP Datasphere. Replication Flow is the cornerstone to fuel SAP Datasphere with data, especially from SAP ABAP sources. There is also a big need to move data from third party sources into SAP Datasphere to succeed certain use cases.
In this part of the Replication Flow Blog series, we focus on the usage of Confluent as a source in Replication Flows. We will explain in detail the new capabilities that have been introduced with SAP Datasphere release 2024.23. The content of this blog is structured as follows.
IntroductionSample Scenario & Confluent specific SetupConfiguration options for Replication FlowsReplication Flow Runtime SpecificsScenarios
1. Introduction
The purpose of the additional features that are described in this Blog, is to provide tailor-made integration with our dedicated partner Confluent’s Apache Kafka®-based data streaming platform—both fully managed Confluent Cloud and self-managed Confluent Platform. More specifically, we now provide the possibility to consume Kafka messages from Confluent, respectively, in SAP Datasphere. The content of this blog does not apply to the generic Kafka integration in SAP Datasphere.
The Confluent integration described in this blog is only usable in SAP Datasphere Replication Flows.
For the examples and step-by-step instructions in the blog, we assume that a properly configured SAP Datasphere tenant and a Confluent Cloud cluster are available. In addition, we assume that the reader is familiar with the basic concepts around Replication Flows and Connection Management in SAP Datasphere as well as with the Kafka data streaming capabilities of Confluent. For a guide on how to setup a connection to Confluent Cloud via the SAP Datasphere Connection Management, we refer the reader to Part 6 of this blog series. If we want to refer/link to Confluent specific material, for the sake of consistency we will always use the Confluent Cloud documentation as well as related material.
2. Overview & Sample Scenario
In order to explain the various aspects of the consumption capabilities in SAP Datasphere Replication Flows for Confluent Kafka data we use the following sample setup. It is solely intended to explain the new functionalities and does not claim to fully or partially represent real scenarios. We assume that we have employee data that is stored in a Kafka topic Demo_Topic consisting of 6 partitions as illustrated in the following figure.
Figure 1 – Kafka Messages with employee data
The employee Kafka messages comply with the following JSON schema whose subject is named Demo_Topic-value and is available in the default schema registry context.
{
“$id”: “http://example.com/myURI.schema.json”,
“$schema”: “http://json-schema.org/draft-07/schema#”,
“additionalProperties”: false,
“description”: “Sample schema”,
“properties”: {
“history”: {
“items”: [
{
“properties”: {
“end”: {
“type”: “string”
},
“position”: {
“type”: “string”
},
“start”: {
“type”: “string”
}
},
“required”: [
“position”,
“start”,
“end”
],
“type”: “object”
}
],
“type”: “array”
},
“id”: {
“type”: “integer”
},
“personal”: {
“properties”: {
“email”: {
“type”: “string”
},
“firstName”: {
“type”: “string”
},
“secondName”: {
“type”: “string”
}
},
“required”: [
“firstName”,
“secondName”,
“email”
],
“type”: “object”
},
“position”: {
“type”: “string”
}
},
“required”: [
“id”,
“personal”,
“position”
],
“title”: “SampleRecord”,
“type”: “object”
}
We will also consider AVRO schemas in this blog.
Confluent Schema Registry is a prerequisite when using a Confluent system as a source in Replication Flows. Additionally, the messages must contain the schema ID in the bytes that follow the magic byte at the beginning of the message. How schemas are used during the replication process is described in the next section.
Replication Flows itself can consume topics with Kafka messages that comply with schemas of type AVRO or JSON.
3. Configuration Options for Replication Flows
We now run through the creation process of a Replication Flow. In parallel we will describe the different configuration options that are available during design time of a Replication Flow in case a Confluent system is selected as the source. For this blog, we use SAP Datasphere as the replication target. Of course, in a real-world scenario, any system that is supported by Replication Flows as a replication target can be used. As mentioned in the first section of this blog, we assume that a connection to the source Confluent system has been set up in the Connection Management. In our case, this connection is named CONFLUENT_DEMO.
After we have entered the Replication Flow creation screen via the , we select CONFLUENT_DEMO as the source connection. A Confluent Schema Context always serves as a Replication Flow Source Container. The default schema context, that we also use in our example, is always denoted with a dot (.). But the Replication Flow Source Container selection screen lists all available schema contexts. In the Replication Flow Source Object selection screen we can choose one or several Kafka topics that are available in the Confluent Cloud cluster. In our example we only select Demo_Topic. Finally, we select the SAP Datasphere local repository as the replication target.
Figure 2 – Replication Flow with Confluent as Source
Although there is no direct relation between Confluent schema contexts and Kafka topics, like it is the case for schemas and tables in classical relational database systems, the two Confluent artifacts are used to derive a structure definition of the replication target (e.g. a HANA table schema in our example). We provide the details below.
As highlighted in Figure 2, for each replication object, in the Object Properties Panel of the Replication Flow screen there are the four standard sections General, Projections, Settings and Target Columns as well as two confluent specific sections Confluent: Source Settings and Confluent: Source Schema Settings. The General and Target Columns section do not require additional explanation.
Settings
It is possible to decide whether Delta Capture Columns are added to the replication target as well as whether the replication target is truncated before the replication starts. For Confluent Kafka sources, only the load type Initial and Delta is supported. Which parts of a topic are actually replicated, depends on the Starting Point that can be configured in the section Confluent: Source Settings (see below).
Figure 3 – General Replication Task Settings
Projections
For each Kafka topic that is added as a source in a Replication Flow there is a projection automatically generated. One can do the usual configurations via the Projection screens.
Figure 4 – Projection Settings
The projection is created automatically due to the way how the Kafka message body of a Kafka message is flattened into a table format. We will provide the details later in the next chapter about Replication Flow Runtime Specifics.
Confluent: Source Schema Settings
The section provides an overview of the Confluent schema that is used to deserialize the Kafka messages of the selected Kafka topic. It also provides a possibility to configure/change the schema that is supposed to be used.
Figure 5 – Source Schema Settings
During the workflow showcased in Figure 2 an initial proposal for the schema to be used, is derived according to the following rules:
The latest message is read from the topic, the schema id is extracted to obtain the schema + subject + version from the schema registry given the specified contextIf there is no message in the Kafka topic, the schema registry (considering the context) is checked for a schema following the topic-name subject naming strategy. If no schema definition is found, no value for the schema is set.If the detected schema is of type PROTOBUF no value is set for the schema.Always the latest version of a detected schema is used
The source Confluent schema, which is a JSON/AVRO nested structure, is then translated into a flat representation according to certain rules (see chapter Replication Flow Runtime Specifics).
In Figure 5 the main area of the schema configuration screen shows the resulting flat representation of the Kafka schema (i.e. viewable via the button Flat) as well as a mapping of the columns of the flat representation to the original nested schema (i.e. viewable via the button Nested). The nested schema uses to specify the data types of the different properties/fields. The Apache Arrow types are only mentioned for the sake of completeness since they are used internally for type mapping.
On the Properties panel on the left side a Confluent schema definition can be selected via Subject Name and a Schema Version dropdown menus.
In addition, one can choose to include/exclude a Technical Key in the target schema. If set, an additional column __message_id of type String(39) is added that constitutes a primary key of the target table derived from the Kafka message in the following way. The value for that column of a row originating from a Kafka message from partition p and offset o is “<p>-<o>”.
Confluent: Source Settings
The section contains configuration options to fine tune the topic consumption behaviour.
Figure 6 – Confluent: Source Settings
The following table lists explains the different configuration options that are shown in Figure 4 above.
Configuration
Value(s)
Explanation
Consume Other Schema Versions
True/False
If set to True, a message (M) that is retrieved and which has a different schema version as opposed to what is configured in the Confluent: Source Schema Settings is tried to be mapped to the configured schema (S) according to the following rules.
Fail if the message has a different serialization type than the schema S specifiesColumns in the message M that are not present in schema S are ignoredColumns that are not present in M but in S are set to NULL in the inferred row. Fail, if the column is part of the primary key.Fail if a column is present in both M and S but has incompatible types.
The Ignore Schema Missmatch configuration allows to configure the behaviour of the replication in case the schema mapping fails.
If set to False, the replication partition will fail with an error stating that the schemas do not match. The subject is always required to be identical to the one specified via the Confluent Source Schema Settings configuration.
Remark:
Schema Compatibility Features of Confluent Schema Registry are not supported.
Ignore Schema Missmatch
True/False
This option is only available if Consume Other Schema is set to True.
If set to True, messages that do not map to the configured schema (see Consume Other Schema Versions) are ignored and the replication continues.
If set to False, the replication partition will fail if a received message with a different schema cannot be mapped to the configured schema.
Fail on Data Truncation
True/False
If set to True, a replication partition fails if a source string field is encountered that does not fit into a string of at most 5000 chars. Also applies to binary values exceeding a length of 5000 bytes.
If set to False, string fields larger than 5000 characters are automatically truncated and written into the target column. The replication continues.
Starting Point
Read from earliest offset / Read from latest offset
Read from earliest offset
The topics are read from the oldest available partition offsets
Read from latest offset
Read only messages newer than the ones present when the replication starts the delta mode phase
4. Replication Flow Run specifics
In this section we will have a closer look on certain behaviour during a replication run. We start with some generic bullet points.
During the replication, all Kafka partitions of the specified source topic are replicated into target. Kafka partitions that are added over time to the source topic are also replicated after some time.Only the content of the Kafka message body is considered for the replication process. Kafka message keys are ignored.Consumption of Kafka messages is always working via the READ_COMMITTED isolation level.
We now provide details regarding the flattening of Kafka source messages.
Message Flattening & Type Mapping
As indicated in the last chapter there is a flattening process involved when setting up and running a Replication Flow. The Confluent schema needs to be flattened into a proper target schema and the content of the Kafka messages need to be translated into the flat target schema. The flattening process for the schema is a two step process. From a high level perspective the flow looks as follows.
Figure 7 – Flattening Process
Let’s take our example topic with the corresponding simplified JSON schema. In the figure below we also added a sample message body and included a possible AVRO schema definition of the JSON schema.
Figure 8 – Sample Schema & Message
In our example the first step is illustrated in the following figure.
Figure 9 – Generating a flat representation of a nested schema
The following rules are applied to flatten the JSON/AVRO schema into the flat Source Schema.
JSON/AVRO Arrays and AVRO Maps are omitted (support for arrays and maps is planned in a subsequent release in 2025)AVRO unions are only supported if and only if there are exactly two types in the union, one of them is the null type and the second type is a supported one.Nested properties are flattened using a naming convention like a simplified JSON path notation.
Using the above sample message, we would end up with the following flattened source message (pseudo notation).
Figure 10 – Example: Flattening Step 1
The second step depends on the target system that was chosen in the Replication Flow UI. In our example the flat target schema looks as follows.
Figure 11 – Generating a flat target schema
In our example, the resulting SAP HANA table in SAP Datasphere looks as follows.
Figure 12 – Sample target table data
The details on the flattening logic provided in this blog will be extended according to subsequent releases and enhancements.
The following two tables show a mapping of the different data types from the source Kafka JSON/AVRO schema, the intermediate flat source schema and the flat target schema. There is also a column which gives information whether a certain source data type is supported or not.
AVRO Type
Arrow Type
HANA Type
Google Big Query
Object Store (parquet)
Object Store (csv)
Comment
null
–
–
–
–
–
ignored
int
ARROW_TYPE_INT32
INTEGER
INT64
INT32
string
Representation in base 10
long
ARROW_TYPE_INT64
BIGINT
INT64
INT64
string
Representation in base 10
float
ARROW_TYPE_FLOAT32
REAL
FLOAT64
FLOAT
string
-ddd.dddd for small (<6) and -d.ddddE±dd for large exponents
double
ARROW_TYPE_FLOAT64
DOUBLE
FLOAT64
DOUBLE
string
-ddd.dddd for small (<6) and -d.ddddE±dd for large exponents
bytes
ARROW_TYPE_BINARY
VARBINARY(5000)
BYTES(n)
BYTE_ARRAY
string
base64 encoding of byte array
Truncation logic is applied
boolean
ARROW_TYPE_BOOLEAN
BOOL
BOOLEAN
string
either true or false
string
ARROW_TYPE_UTF8
NVARCHAR(5000)
STRING(N)
BYTE_ARRAY
string
Truncation logic is applied
records
StructType
–
–
–
–
Resolved via flattening
enum
ARROW_TYPE_UTF8(length N)
NVARCHAR(N)
STRING(N)
BYTE_ARRAY
string
The length N is defined by the maximum length of the enum values
array
–
–
–
–
–
Not supported
map
–
–
–
–
–
Not supported
union
n/a
Depends on type that is used in the union (see comment)
Depends on type that is used in the union (see comment)
Depends on type that is used in the union (see comment)
Depends on type that is used in the union (see comment)
Only support [“null”, <some-type>]
fixed(N)
ARROW_TYPE_FIXEDSIZEBINARY(length N)
VARBINARY(N)
BYTES(N)
BYTE_ARRAY
string
base64 encoding of byte array
decimal(p,s)
ARROW_TYPE_DECIMAL128/
ARROW_TYPE_DECIMAL256(p,s)
DECIMAL(p,s)
NUMERIC(p,s)
FIXED_LEN_BYTE_ARRAY
DECIMAL(s,p)
string
uuid
ARROW_TYPE_UTF8
NCLOB
–
BYTE_ARRAY
string
date
ARROW_TYPE_DATEDAY
DATE
DATE
INT32
DATE
string
YYYY-MM-DD
time-millis
ARROW_TYPE_TIMEMILLI
TIME
TIME
string
HH:MM:SS.NNNNNNNNN (nanosecond precision)
time-micros
ARROW_TYPE_TIMEMICRO
TIME
TIME
INT64
TIME(microseconds)
string
HH:MM:SS.NNNNNNNNN (nanosecond precision)
timestamp-millis
ARROW_TYPE_TIMESTAMPMILLITZ
TIMESTAMP
TIMESTAMP
string
YYYY-MM-DD HH:MM:SS.NNNNNNNNN (nanosecond precision)
timestamp-micros
ARROW_TYPE_TIMESTAMPMICROTZ
TIMESTAMP
TIMESTAMP
INT64
TIMESTAMP(microseconds)
string
YYYY-MM-DD HH:MM:SS.NNNNNNNNN (nanosecond precision)
local-timestamp-millis
ARROW_TYPE_TIMESTAMPMILLI
TIMESTAMP
TIMESTAMP
string
YYYY-MM-DD HH:MM:SS.NNNNNNNNN (nanosecond precision)
Local-timestamp-micros
ARROW_TYPE_TIMESTAMPMICRO
TIMESTAMP
TIMESTAMP
INT64
TIMESTAMP(microseconds)
string
YYYY-MM-DD HH:MM:SS.NNNNNNNNN (nanosecond precision)
duration
ARROW_TYPE_INTERVALMONTHDAYNANO
–
–
–
–
JSON as schema type
JSON Type
Arrow Type
HANA Type
Google Big Query
Object Store (parquet)
Object Store (csv)
Comment
string
ARROW_TYPE_UTF8
NVARCHAR(5000)
STRING(5000)
BYTE_ARRAY
string
number
ARROW_TYPE_FLOAT64
DOUBLE
FLOAT64
DOUBLE
string
-ddd.dddd for small (<6) and -d.ddddE±dd for large exponents
integer
ARROW_TYPE_INT64
BIGINT
INT64
INT64
string
Representation in base 10
object
StructType
–
–
–
–
Resolved via flattening
array
–
–
–
–
–
Not supported
boolean
ARROW_TYPE_BOOLEAN
BOOLEAN
BOOL
BOOLEAN
string
either true or false
null
None, ignored.
–
–
–
–
string with format date-time
ARROW_TYPE_TIMESTAMPNANOTZ
TIMESTAMP
TIMESTAMP
INT64
TIMESTAMP(microseconds)
string
YYYY-MM-DD HH:MM:SS.NNNNNNNNN (nanosecond precision)
string with format time
ARROW_TYPE_TIMENANO
TIME
TIME
INT64
TIME(microseconds)
string
HH:MM:SS.NNNNNNNNN (nanosecond precision)
string with format date
ARROW_TYPE_DATEDAY
DATE
DATE
INT32
DATE
string
YYYY-MM-DD
We end this blog with a short remark regarding replication fails.
Failing a Replication from a Confluent Kafka source partition
As outlined in the chapter above about Configuration Options for Replication Flows the replication might fail because of various reasons, for example if the Fail on Data Truncation flag is turned on or if a message uses a wrong schema. In case such a replication failure occurs the replication is only stopped for the corresponding source Kafka partition that contains the message that caused the failure. It is currently not possible to automatically stop the full Replication Task or Flow in case a replication failure occurs during the replication of a specific source Kafka partition.
This blog is part of a blog series from SAP Datasphere product management with the focus on the Replication Flow capabilities in SAP Datasphere: Replication Flow Blog Series Part 1 – Overview | SAP Blogs Replication Flow Blog Series Part 2 – Premium Outbound Integration | SAP Blogs Replication Flows Blog Series Part 3 – Integration with Kafka Replication Flows Blog Series Part 4 – Sizing Replication Flows Blog Series Part 5 – Integration between SAP Datasphere and Databricks Replication Flows Blog Series Part 6 – Confluent as a Replication TargetReplication Flows Blog Series Part 7 – PerformanceReplication Flows Blog Series Part 8 – Confluent as a Replication SourceData Integration is an essential topic in a Business Data Fabric like SAP Datasphere. Replication Flow is the cornerstone to fuel SAP Datasphere with data, especially from SAP ABAP sources. There is also a big need to move data from third party sources into SAP Datasphere to succeed certain use cases. In this part of the Replication Flow Blog series, we focus on the usage of Confluent as a source in Replication Flows. We will explain in detail the new capabilities that have been introduced with SAP Datasphere release 2024.23. The content of this blog is structured as follows.IntroductionSample Scenario & Confluent specific SetupConfiguration options for Replication FlowsReplication Flow Runtime SpecificsScenarios 1. IntroductionThe purpose of the additional features that are described in this Blog, is to provide tailor-made integration with our dedicated partner Confluent’s Apache Kafka®-based data streaming platform—both fully managed Confluent Cloud and self-managed Confluent Platform. More specifically, we now provide the possibility to consume Kafka messages from Confluent, respectively, in SAP Datasphere. The content of this blog does not apply to the generic Kafka integration in SAP Datasphere.The Confluent integration described in this blog is only usable in SAP Datasphere Replication Flows.For the examples and step-by-step instructions in the blog, we assume that a properly configured SAP Datasphere tenant and a Confluent Cloud cluster are available. In addition, we assume that the reader is familiar with the basic concepts around Replication Flows and Connection Management in SAP Datasphere as well as with the Kafka data streaming capabilities of Confluent. For a guide on how to setup a connection to Confluent Cloud via the SAP Datasphere Connection Management, we refer the reader to Part 6 of this blog series. If we want to refer/link to Confluent specific material, for the sake of consistency we will always use the Confluent Cloud documentation as well as related material. 2. Overview & Sample ScenarioIn order to explain the various aspects of the consumption capabilities in SAP Datasphere Replication Flows for Confluent Kafka data we use the following sample setup. It is solely intended to explain the new functionalities and does not claim to fully or partially represent real scenarios. We assume that we have employee data that is stored in a Kafka topic Demo_Topic consisting of 6 partitions as illustrated in the following figure.Figure 1 – Kafka Messages with employee dataThe employee Kafka messages comply with the following JSON schema whose subject is named Demo_Topic-value and is available in the default schema registry context. {
“$id”: “http://example.com/myURI.schema.json”,
“$schema”: “http://json-schema.org/draft-07/schema#”,
“additionalProperties”: false,
“description”: “Sample schema”,
“properties”: {
“history”: {
“items”: [
{
“properties”: {
“end”: {
“type”: “string”
},
“position”: {
“type”: “string”
},
“start”: {
“type”: “string”
}
},
“required”: [
“position”,
“start”,
“end”
],
“type”: “object”
}
],
“type”: “array”
},
“id”: {
“type”: “integer”
},
“personal”: {
“properties”: {
“email”: {
“type”: “string”
},
“firstName”: {
“type”: “string”
},
“secondName”: {
“type”: “string”
}
},
“required”: [
“firstName”,
“secondName”,
“email”
],
“type”: “object”
},
“position”: {
“type”: “string”
}
},
“required”: [
“id”,
“personal”,
“position”
],
“title”: “SampleRecord”,
“type”: “object”
} We will also consider AVRO schemas in this blog.Confluent Schema Registry is a prerequisite when using a Confluent system as a source in Replication Flows. Additionally, the messages must contain the schema ID in the bytes that follow the magic byte at the beginning of the message. How schemas are used during the replication process is described in the next section.Replication Flows itself can consume topics with Kafka messages that comply with schemas of type AVRO or JSON. 3. Configuration Options for Replication FlowsWe now run through the creation process of a Replication Flow. In parallel we will describe the different configuration options that are available during design time of a Replication Flow in case a Confluent system is selected as the source. For this blog, we use SAP Datasphere as the replication target. Of course, in a real-world scenario, any system that is supported by Replication Flows as a replication target can be used. As mentioned in the first section of this blog, we assume that a connection to the source Confluent system has been set up in the Connection Management. In our case, this connection is named CONFLUENT_DEMO.After we have entered the Replication Flow creation screen via the , we select CONFLUENT_DEMO as the source connection. A Confluent Schema Context always serves as a Replication Flow Source Container. The default schema context, that we also use in our example, is always denoted with a dot (.). But the Replication Flow Source Container selection screen lists all available schema contexts. In the Replication Flow Source Object selection screen we can choose one or several Kafka topics that are available in the Confluent Cloud cluster. In our example we only select Demo_Topic. Finally, we select the SAP Datasphere local repository as the replication target.Figure 2 – Replication Flow with Confluent as SourceAlthough there is no direct relation between Confluent schema contexts and Kafka topics, like it is the case for schemas and tables in classical relational database systems, the two Confluent artifacts are used to derive a structure definition of the replication target (e.g. a HANA table schema in our example). We provide the details below.As highlighted in Figure 2, for each replication object, in the Object Properties Panel of the Replication Flow screen there are the four standard sections General, Projections, Settings and Target Columns as well as two confluent specific sections Confluent: Source Settings and Confluent: Source Schema Settings. The General and Target Columns section do not require additional explanation.SettingsIt is possible to decide whether Delta Capture Columns are added to the replication target as well as whether the replication target is truncated before the replication starts. For Confluent Kafka sources, only the load type Initial and Delta is supported. Which parts of a topic are actually replicated, depends on the Starting Point that can be configured in the section Confluent: Source Settings (see below).Figure 3 – General Replication Task SettingsProjectionsFor each Kafka topic that is added as a source in a Replication Flow there is a projection automatically generated. One can do the usual configurations via the Projection screens.Figure 4 – Projection SettingsThe projection is created automatically due to the way how the Kafka message body of a Kafka message is flattened into a table format. We will provide the details later in the next chapter about Replication Flow Runtime Specifics.Confluent: Source Schema SettingsThe section provides an overview of the Confluent schema that is used to deserialize the Kafka messages of the selected Kafka topic. It also provides a possibility to configure/change the schema that is supposed to be used.Figure 5 – Source Schema SettingsDuring the workflow showcased in Figure 2 an initial proposal for the schema to be used, is derived according to the following rules:The latest message is read from the topic, the schema id is extracted to obtain the schema + subject + version from the schema registry given the specified contextIf there is no message in the Kafka topic, the schema registry (considering the context) is checked for a schema following the topic-name subject naming strategy. If no schema definition is found, no value for the schema is set.If the detected schema is of type PROTOBUF no value is set for the schema.Always the latest version of a detected schema is usedThe source Confluent schema, which is a JSON/AVRO nested structure, is then translated into a flat representation according to certain rules (see chapter Replication Flow Runtime Specifics).In Figure 5 the main area of the schema configuration screen shows the resulting flat representation of the Kafka schema (i.e. viewable via the button Flat) as well as a mapping of the columns of the flat representation to the original nested schema (i.e. viewable via the button Nested). The nested schema uses to specify the data types of the different properties/fields. The Apache Arrow types are only mentioned for the sake of completeness since they are used internally for type mapping.On the Properties panel on the left side a Confluent schema definition can be selected via Subject Name and a Schema Version dropdown menus.In addition, one can choose to include/exclude a Technical Key in the target schema. If set, an additional column __message_id of type String(39) is added that constitutes a primary key of the target table derived from the Kafka message in the following way. The value for that column of a row originating from a Kafka message from partition p and offset o is “<p>-<o>”.Confluent: Source SettingsThe section contains configuration options to fine tune the topic consumption behaviour.Figure 6 – Confluent: Source SettingsThe following table lists explains the different configuration options that are shown in Figure 4 above.ConfigurationValue(s)ExplanationConsume Other Schema VersionsTrue/FalseIf set to True, a message (M) that is retrieved and which has a different schema version as opposed to what is configured in the Confluent: Source Schema Settings is tried to be mapped to the configured schema (S) according to the following rules.Fail if the message has a different serialization type than the schema S specifiesColumns in the message M that are not present in schema S are ignoredColumns that are not present in M but in S are set to NULL in the inferred row. Fail, if the column is part of the primary key.Fail if a column is present in both M and S but has incompatible types.The Ignore Schema Missmatch configuration allows to configure the behaviour of the replication in case the schema mapping fails.If set to False, the replication partition will fail with an error stating that the schemas do not match. The subject is always required to be identical to the one specified via the Confluent Source Schema Settings configuration.Remark:Schema Compatibility Features of Confluent Schema Registry are not supported.Ignore Schema MissmatchTrue/FalseThis option is only available if Consume Other Schema is set to True.If set to True, messages that do not map to the configured schema (see Consume Other Schema Versions) are ignored and the replication continues.If set to False, the replication partition will fail if a received message with a different schema cannot be mapped to the configured schema.Fail on Data TruncationTrue/FalseIf set to True, a replication partition fails if a source string field is encountered that does not fit into a string of at most 5000 chars. Also applies to binary values exceeding a length of 5000 bytes.If set to False, string fields larger than 5000 characters are automatically truncated and written into the target column. The replication continues.Starting PointRead from earliest offset / Read from latest offsetRead from earliest offsetThe topics are read from the oldest available partition offsetsRead from latest offsetRead only messages newer than the ones present when the replication starts the delta mode phase 4. Replication Flow Run specificsIn this section we will have a closer look on certain behaviour during a replication run. We start with some generic bullet points.During the replication, all Kafka partitions of the specified source topic are replicated into target. Kafka partitions that are added over time to the source topic are also replicated after some time.Only the content of the Kafka message body is considered for the replication process. Kafka message keys are ignored.Consumption of Kafka messages is always working via the READ_COMMITTED isolation level. We now provide details regarding the flattening of Kafka source messages.Message Flattening & Type MappingAs indicated in the last chapter there is a flattening process involved when setting up and running a Replication Flow. The Confluent schema needs to be flattened into a proper target schema and the content of the Kafka messages need to be translated into the flat target schema. The flattening process for the schema is a two step process. From a high level perspective the flow looks as follows.Figure 7 – Flattening ProcessLet’s take our example topic with the corresponding simplified JSON schema. In the figure below we also added a sample message body and included a possible AVRO schema definition of the JSON schema.Figure 8 – Sample Schema & MessageIn our example the first step is illustrated in the following figure.Figure 9 – Generating a flat representation of a nested schemaThe following rules are applied to flatten the JSON/AVRO schema into the flat Source Schema.JSON/AVRO Arrays and AVRO Maps are omitted (support for arrays and maps is planned in a subsequent release in 2025)AVRO unions are only supported if and only if there are exactly two types in the union, one of them is the null type and the second type is a supported one.Nested properties are flattened using a naming convention like a simplified JSON path notation.Using the above sample message, we would end up with the following flattened source message (pseudo notation).Figure 10 – Example: Flattening Step 1The second step depends on the target system that was chosen in the Replication Flow UI. In our example the flat target schema looks as follows.Figure 11 – Generating a flat target schemaIn our example, the resulting SAP HANA table in SAP Datasphere looks as follows.Figure 12 – Sample target table dataThe details on the flattening logic provided in this blog will be extended according to subsequent releases and enhancements.The following two tables show a mapping of the different data types from the source Kafka JSON/AVRO schema, the intermediate flat source schema and the flat target schema. There is also a column which gives information whether a certain source data type is supported or not.AVRO TypeArrow TypeHANA TypeGoogle Big QueryObject Store (parquet)Object Store (csv)Commentnull—–ignoredintARROW_TYPE_INT32INTEGERINT64INT32stringRepresentation in base 10 longARROW_TYPE_INT64BIGINTINT64INT64stringRepresentation in base 10 floatARROW_TYPE_FLOAT32REALFLOAT64FLOATstring-ddd.dddd for small (<6) and -d.ddddE±dd for large exponents doubleARROW_TYPE_FLOAT64DOUBLEFLOAT64DOUBLEstring-ddd.dddd for small (<6) and -d.ddddE±dd for large exponents bytesARROW_TYPE_BINARYVARBINARY(5000)BYTES(n)BYTE_ARRAYstringbase64 encoding of byte arrayTruncation logic is appliedbooleanARROW_TYPE_BOOLEAN BOOLBOOLEANstringeither true or false stringARROW_TYPE_UTF8NVARCHAR(5000)STRING(N)BYTE_ARRAYstringTruncation logic is appliedrecordsStructType—-Resolved via flatteningenumARROW_TYPE_UTF8(length N)NVARCHAR(N)STRING(N)BYTE_ARRAYstringThe length N is defined by the maximum length of the enum valuesarray—–Not supportedmap—–Not supportedunionn/aDepends on type that is used in the union (see comment)Depends on type that is used in the union (see comment)Depends on type that is used in the union (see comment)Depends on type that is used in the union (see comment)Only support [“null”, <some-type>]fixed(N)ARROW_TYPE_FIXEDSIZEBINARY(length N)VARBINARY(N)BYTES(N)BYTE_ARRAYstringbase64 encoding of byte array decimal(p,s)ARROW_TYPE_DECIMAL128/ARROW_TYPE_DECIMAL256(p,s)DECIMAL(p,s)NUMERIC(p,s)FIXED_LEN_BYTE_ARRAYDECIMAL(s,p)string uuidARROW_TYPE_UTF8NCLOB-BYTE_ARRAYstring dateARROW_TYPE_DATEDAYDATEDATEINT32DATEstringYYYY-MM-DD time-millisARROW_TYPE_TIMEMILLITIMETIME stringHH:MM:SS.NNNNNNNNN (nanosecond precision) time-microsARROW_TYPE_TIMEMICROTIMETIMEINT64TIME(microseconds)stringHH:MM:SS.NNNNNNNNN (nanosecond precision) timestamp-millisARROW_TYPE_TIMESTAMPMILLITZTIMESTAMPTIMESTAMP stringYYYY-MM-DD HH:MM:SS.NNNNNNNNN (nanosecond precision) timestamp-microsARROW_TYPE_TIMESTAMPMICROTZTIMESTAMPTIMESTAMPINT64TIMESTAMP(microseconds)stringYYYY-MM-DD HH:MM:SS.NNNNNNNNN (nanosecond precision) local-timestamp-millisARROW_TYPE_TIMESTAMPMILLITIMESTAMPTIMESTAMP stringYYYY-MM-DD HH:MM:SS.NNNNNNNNN (nanosecond precision) Local-timestamp-microsARROW_TYPE_TIMESTAMPMICROTIMESTAMPTIMESTAMPINT64TIMESTAMP(microseconds)stringYYYY-MM-DD HH:MM:SS.NNNNNNNNN (nanosecond precision) durationARROW_TYPE_INTERVALMONTHDAYNANO—- JSON as schema typeJSON TypeArrow TypeHANA TypeGoogle Big QueryObject Store (parquet)Object Store (csv)CommentstringARROW_TYPE_UTF8NVARCHAR(5000)STRING(5000)BYTE_ARRAYstring numberARROW_TYPE_FLOAT64DOUBLEFLOAT64DOUBLEstring-ddd.dddd for small (<6) and -d.ddddE±dd for large exponents integerARROW_TYPE_INT64BIGINTINT64INT64stringRepresentation in base 10 objectStructType—-Resolved via flatteningarray—–Not supportedbooleanARROW_TYPE_BOOLEANBOOLEANBOOLBOOLEANstringeither true or false nullNone, ignored.—- string with format date-timeARROW_TYPE_TIMESTAMPNANOTZTIMESTAMPTIMESTAMPINT64TIMESTAMP(microseconds)stringYYYY-MM-DD HH:MM:SS.NNNNNNNNN (nanosecond precision) string with format timeARROW_TYPE_TIMENANOTIMETIMEINT64TIME(microseconds)stringHH:MM:SS.NNNNNNNNN (nanosecond precision) string with format dateARROW_TYPE_DATEDAYDATEDATEINT32DATEstringYYYY-MM-DD We end this blog with a short remark regarding replication fails.Failing a Replication from a Confluent Kafka source partitionAs outlined in the chapter above about Configuration Options for Replication Flows the replication might fail because of various reasons, for example if the Fail on Data Truncation flag is turned on or if a message uses a wrong schema. In case such a replication failure occurs the replication is only stopped for the corresponding source Kafka partition that contains the message that caused the failure. It is currently not possible to automatically stop the full Replication Task or Flow in case a replication failure occurs during the replication of a specific source Kafka partition. Read More Technology Blogs by SAP articles
#SAP
#SAPTechnologyblog