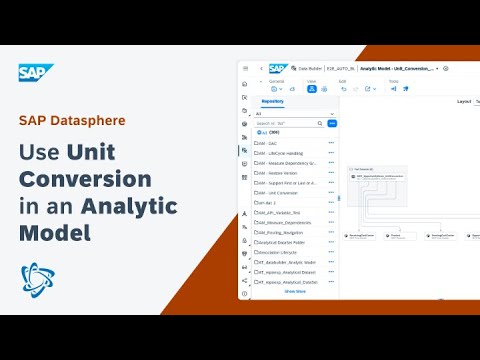
Traditional models for machine learning are good at handling structured (or tabular) data. However, nowadays more and more tabular data are collected in accompany with non-structured data. Text is one of the most popular form of non-structured data, e. g. comments and reviews in commercial data. In such cases, it is of vital importance that we can efficiently utilize the non-structured text sin order to fully explore the potential power of the full datasets (inclusive of both structured features and non-structured texts). Text embedding is currently recognized as one of the most effective way handle the non-structured text data, which transforms texts into real vectors of prescribed length that are structured. Thus, we can possibly enhance the performance of traditional machine learning models by treating text embedding as a processing step, and enrich their support for embedding vectors.
Traditional models for machine learning are good at handling structured (or tabular) data. However, nowadays more and more tabular data are collected in accompany with non-structured data. Text is one of the most popular form of non-structured data, e. g. comments and reviews in commercial data. In such cases, it is of vital importance that we can efficiently utilize the non-structured text sin order to fully explore the potential power of the full datasets (inclusive of both structured features and non-structured texts). Text embedding is currently recognized as one of the most effective way handle the non-structured text data, which transforms texts into real vectors of prescribed length that are structured. Thus, we can possibly enhance the performance of traditional machine learning models by treating text embedding as a processing step, and enrich their support for embedding vectors. Read More Technology Blogs by SAP articles
#SAP
#SAPTechnologyblog