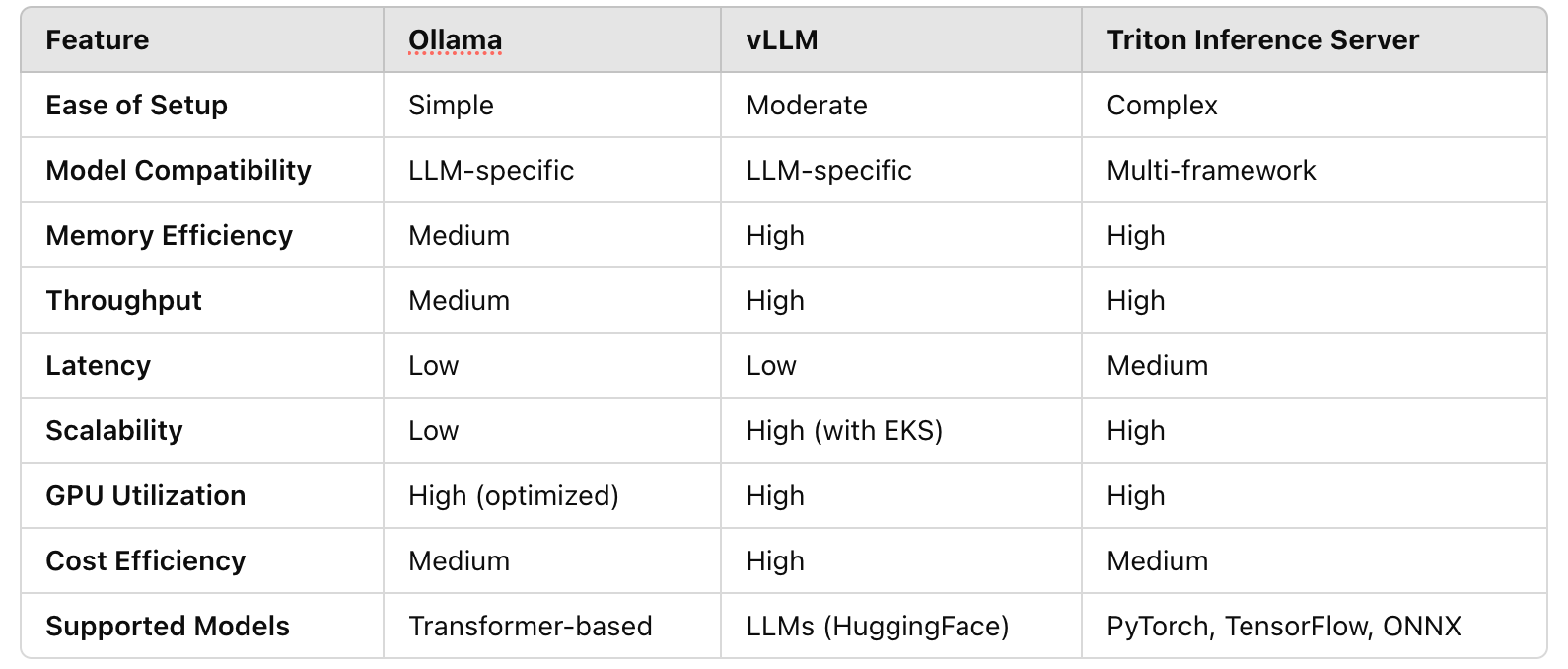
Building an Inference Server on AWS (EC2 or EKS) Using Ollama, vLLM, or Triton January 10, 2025 Estimated read time 1 min read Introduction Continue reading on Medium » IntroductionContinue reading on Medium » Read More Llm on Medium #AI
Developing a RAG (Retrieval-Augmented Generation) and LLM (Large Language Model) application… January 10, 2025
Developing a RAG (Retrieval-Augmented Generation) and LLM (Large Language Model) application… January 10, 2025