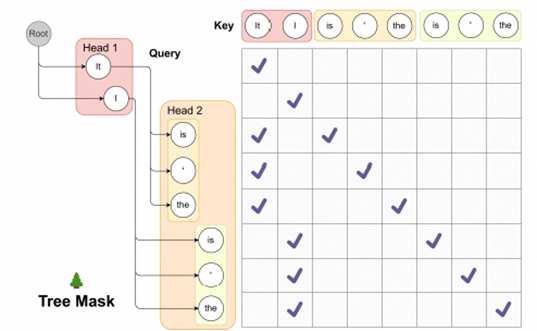
Deploying models on live production systems is challenging and improving latency is one of the biggest challenges; we can also reduce costs
Continue reading on AI Practice and Data Engineering Practice, GovTech »
Deploying models on live production systems is challenging and improving latency is one of the biggest challenges; we can also reduce costsContinue reading on AI Practice and Data Engineering Practice, GovTech » Read More Llm on Medium
#AI