A Guide to Using Semantic Cache to Speed Up LLM Queries with Qdrant and Groq. May 21, 2024 Estimated read time 1 min read Continue reading on Stackademic » Continue reading on Stackademic » Read More AI on Medium #AI
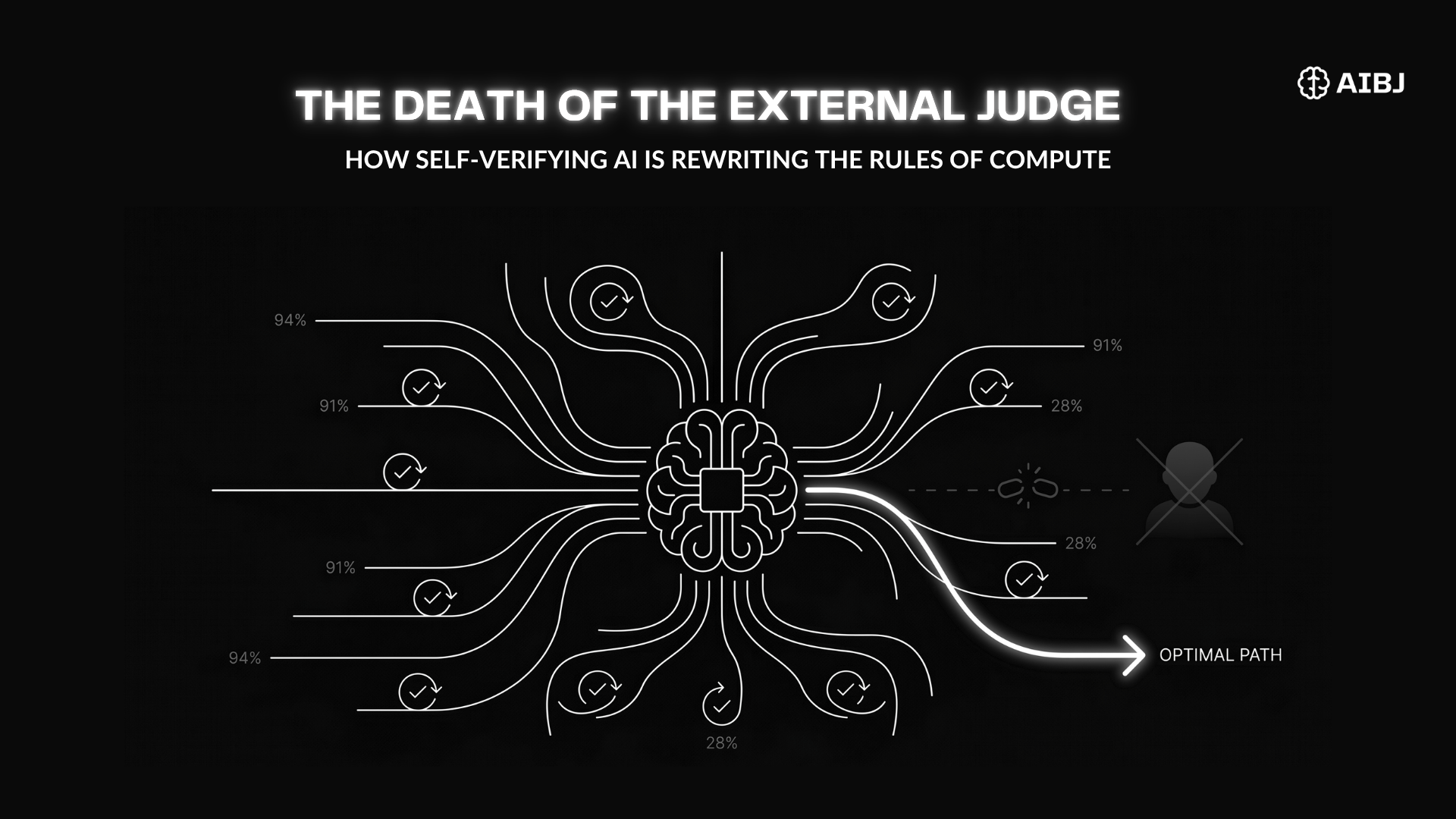
The Death of the External Judge: How Self-Verifying AI is Rewriting the Rules of Compute June 24, 2026
The Death of the External Judge: How Self-Verifying AI is Rewriting the Rules of Compute June 24, 2026
AI The Death of the External Judge: How Self-Verifying AI is Rewriting the Rules of Compute June 24, 2026
Bike No Derailleur, No Cassette: Gobao’s New 1500W Motor Eliminates Traditional Shifting June 24, 2026













+ There are no comments
Add yours