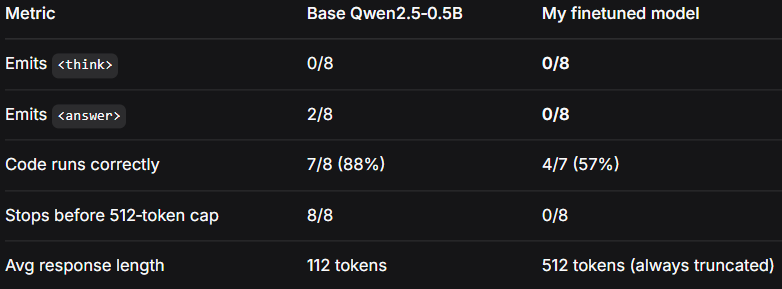
Go beyond the “stateless” myth. This deep dive into Prompt Caching (OpenAI, Gemini, Anthropic) explains the essential difference between caching the input and generating a fresh output, revealing why LLM responses vary even at a strict Temperature=0. We analyze the technical physics behind this non-determinism (MoE architecture, GPU math) and share a crucial developer insight: why adding a single word to your prompt can suddenly fix a sequence of consistently flawed code generations, ensuring you optimize your agentic workflows for maximum speed and quality.
Go beyond the “stateless” myth. This deep dive into Prompt Caching (OpenAI, Gemini, Anthropic) explains the essential difference between caching the input and generating a fresh output, revealing why LLM responses vary even at a strict Temperature=0. We analyze the technical physics behind this non-determinism (MoE architecture, GPU math) and share a crucial developer insight: why adding a single word to your prompt can suddenly fix a sequence of consistently flawed code generations, ensuring you optimize your agentic workflows for maximum speed and quality. Read More Technology Blog Posts by SAP articles
#SAP
#SAPTechnologyblog